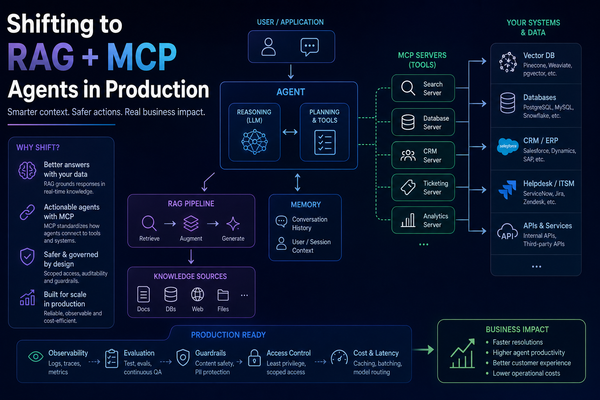
6. GraphRAG - Multi-Hop Reasoning with a Local Knowledge Graph
Go beyond flat vector search. Build a knowledge graph from your documents, run multi-hop queries that traverse entity relationships, and combine graph traversal with vector retrieval for richer answers.

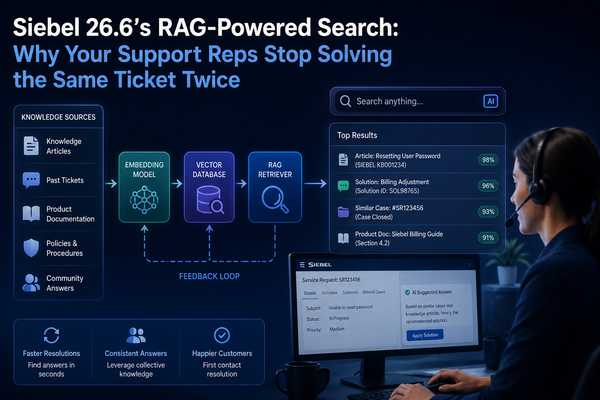
GraphRAG
Multi-Hop Reasoning with a Local Knowledge Graph
Vector search finds similar text. A knowledge graph finds connected facts. This article adds NetworkX graph construction and traversal to the Article 3 API so it can answer questions that require chaining information across multiple documents.
🔍Where Vector RAG Fails
Standard RAG retrieves the chunks most semantically similar to the question. This works brilliantly for single-hop questions - ones whose answer lives in a single chunk. It breaks down for multi-hop questions - ones that require combining facts from different chunks that share no embedding similarity with each other.
The question "Which company did the CEO of Acme Corp found?" requires two facts: (1) Alice Lee is the CEO of Acme Corp, and (2) Alice Lee co-founded DataBridge. Chunk A is similar to the question and gets retrieved. Chunk B mentions Alice Lee in a different context - its embedding is far from "CEO Acme Corp" - so standard retrieval misses it entirely.
A knowledge graph traverses the entity connection: Acme Corp → CEO → Alice Lee → co-founded → DataBridge. Both chunks are found through structural reasoning, not embedding similarity.
Multi-hop questions are common in real-world corpora: product manuals (component A references component B), research papers (study X cites study Y), legal documents (clause 3 references section 7). If your RAG system can't chain two facts it will consistently fail on these.
🕸Knowledge Graphs 101
A knowledge graph is a directed graph where nodes are entities (people, places, organizations, concepts) and edges are relationships between them. Each edge has a label - the predicate - that describes the nature of the connection.
The atomic unit is a triple: (subject, predicate, object). Every fact in the graph is represented as one triple:
At query time, we extract entities from the question, find their corresponding graph nodes, and do a breadth-first traversal up to N hops. Each traversed edge leads us to the chunk it came from, surfacing related facts that embedding similarity would never find.
This is not Microsoft's GraphRAG. The Microsoft paper uses community detection, hierarchical summaries, and global query answering - and requires a powerful LLM (GPT-4 class). Our approach is a simpler, practical subset: local triple extraction + graph traversal for multi-hop retrieval. It runs entirely on local Ollama models and is much cheaper to build and operate.
🏗Architecture Overview
The system has two distinct phases: an offline build phase (extract triples, build graph) and an online query phase (hybrid retrieval + generation).
🧰Technology Stack
NetworkX 3.4
Pure-Python graph library. We use MultiDiGraph - directed (subject → object) and multi-edge (multiple relationships between the same two entities). Persisted as JSON via node_link_data(). Zero external services required.
Ollama NER prompting
No dedicated NER model needed. A zero-shot prompt asking the LLM to produce JSON triples works surprisingly well with llama3.2:3b. The same model used for generation is reused for extraction - no additional download.
Hybrid: vector + graph
ChromaDB handles semantic similarity (same as Article 3). NetworkX handles structural traversal. The results are merged: graph contexts appear first in the prompt so the generation model sees multi-hop evidence before the semantic matches.
knowledge_graph.json
NetworkX's node_link_data() format. Readable, diffable, and trivial to inspect. Each node stores a set of chunk_ids; each edge stores the predicate and originating chunk_id so text can be retrieved later.
⚙️Project Setup
One new dependency on top of the Article 3 stack:
pip install networkx==3.4.2
Add the new files to the Article 3 project root:
project/ ├── main.py # add graph router ├── graph_builder.py # NEW - triple extraction + NetworkX graph ├── graph_retriever.py # NEW - hybrid retrieval ├── knowledge_graph.json # generated, git-ignored └── routers/ └── graph.py # NEW - /graph/* endpoints
from routers import documents, query, graph # add graph app.include_router(graph.router)
🔬Extracting Triples
For each document chunk, we send a zero-shot prompt to Ollama asking it to extract all factual relationships as JSON triples. The key design choice is to ask for lowercase, short entity names - this dramatically improves the chance that the same entity appears identically across different chunks.
_TRIPLE_PROMPT = """\ Extract factual relationships from the text as (subject, predicate, object) triples. Use short, lowercase names for entities. Reply ONLY with a JSON array - no markdown: [{{"s": "entity", "p": "relation", "o": "entity"}}, ...] If there are no clear relationships, reply with an empty array: [] Text: {chunk}""" def _extract_triples(chunk: str, chunk_id: str) -> list[dict]: try: resp = ollama.chat( model=_EXTRACTOR_MODEL, messages=[{"role": "user", "content": _TRIPLE_PROMPT.format(chunk=chunk)}], options={"temperature": 0, "num_predict": 512}, ) raw = resp["message"]["content"].strip() # strip markdown fences if the model wrapped the JSON if raw.startswith("```"): raw = raw.split("```")[1].lstrip("json").strip() triples = json.loads(raw) return [ { "s": str(t["s"]).strip().lower(), "p": str(t["p"]).strip().lower(), "o": str(t["o"]).strip().lower(), "chunk_id": chunk_id, } for t in triples if isinstance(t, dict) and {"s", "p", "o"} <= t.keys() ] except (json.JSONDecodeError, KeyError, TypeError) as exc: log.warning("Extraction failed (chunk=%s): %s", chunk_id, exc) return []
What the LLM produces
Given the chunk "Alice Lee is the CEO of Acme Corp. She previously worked at TechCorp and co-founded DataBridge in 2019.", the model returns:
[
{"s": "alice lee", "p": "ceo of", "o": "acme corp"},
{"s": "alice lee", "p": "previously worked at", "o": "techcorp"},
{"s": "alice lee", "p": "co-founded", "o": "databrige"},
{"s": "databrige", "p": "founded in", "o": "2019"}
]
"alice lee" and Chunk B produces "alice" or "ms. lee", the graph has three separate nodes with no connection. Graph traversal starting at "alice lee" never reaches the other nodes._extract_triples() helps but doesn't fully solve it. For production, add a canonicalization step: after building the graph, merge nodes whose names have edit distance ≤ 2 or share a common alias. For a tutorial corpus, lowercasing is sufficient.🔷Building the Graph
We use NetworkX's MultiDiGraph - directed (edges go from subject to object) and multi-edge (the same two entities can have multiple different relationships). Each node stores the set of chunk IDs it was mentioned in; each edge stores the predicate and the chunk it came from.
import networkx as nx def build( chunks: list[tuple[str, str]], # [(chunk_id, text), ...] model: str = "llama3.2:3b", ) -> nx.MultiDiGraph: G: nx.MultiDiGraph = load() # incremental - keeps existing graph for chunk_id, text in chunks: triples = _extract_triples(text, chunk_id) for t in triples: # Upsert nodes - accumulate all chunk_ids that mention this entity for entity in (t["s"], t["o"]): if not G.has_node(entity): G.add_node(entity, chunk_ids=set()) G.nodes[entity]["chunk_ids"] |= {chunk_id} # Directed edge: subject → object, labeled with predicate G.add_edge(t["s"], t["o"], relation=t["p"], chunk_id=chunk_id) save(G) return G def save(G: nx.MultiDiGraph) -> None: data = nx.node_link_data(G) # sets aren't JSON-serialisable - convert before saving for node in data["nodes"]: if isinstance(node.get("chunk_ids"), set): node["chunk_ids"] = list(node["chunk_ids"]) GRAPH_PATH.write_text(json.dumps(data, indent=2)) def load() -> nx.MultiDiGraph: if not GRAPH_PATH.exists(): return nx.MultiDiGraph() G = nx.node_link_graph( json.loads(GRAPH_PATH.read_text()), directed=True, multigraph=True, ) # restore chunk_ids as sets for O(1) union operations for _, attrs in G.nodes(data=True): if isinstance(attrs.get("chunk_ids"), list): attrs["chunk_ids"] = set(attrs["chunk_ids"]) return G
build() calls load() first, so it's incremental - running it again after adding new documents extends the graph without rebuilding from scratch. Re-processing a chunk that's already in the graph only adds duplicate edges, which MultiDiGraph handles correctly (they're keyed by edge index).
⚡Hybrid Retrieval
At query time, graph_retriever.py runs two parallel lookups and merges the results. The critical design decision: graph contexts go first in the prompt. They contain the multi-hop relational evidence the LLM needs, and LLMs tend to weight earlier context more heavily.
def retrieve( question: str, collection: chromadb.Collection, G: nx.MultiDiGraph, model: str = "llama3.2:3b", vector_k: int = 4, graph_k: int = 3, max_hops: int = 2, ) -> list[Context]: # 1. Vector search (ChromaDB) - semantic similarity vr = collection.query( query_texts=[question], n_results=vector_k, include=["documents", "distances"] ) vector_contexts = [ Context(text=doc, source="vector", score=round(1.0 - dist, 4)) for doc, dist in zip(vr["documents"][0], vr["distances"][0]) ] if G.number_of_nodes() == 0: return vector_contexts # graceful fallback: graph not built yet # 2. Entity extraction from the question entities = _entities_from_question(question, model) # 3. Fuzzy match: find graph nodes that overlap with entities seed_nodes = _fuzzy_match_nodes(entities, G) # 4. BFS from seed nodes - collect texts of traversed chunk_ids graph_contexts = _traverse(seed_nodes, G, collection, max_hops, graph_k) # 5. Deduplicate: drop graph results already present in vector results vector_texts = {c.text for c in vector_contexts} unique_graph = [c for c in graph_contexts if c.text not in vector_texts] # Graph contexts first - multi-hop evidence seen before semantic matches return unique_graph + vector_contexts
The BFS traversal
def _traverse( seed_nodes: list[str], G: nx.MultiDiGraph, collection: chromadb.Collection, max_hops: int, max_contexts: int, ) -> list[Context]: seen_chunks: set[str] = set() contexts: list[Context] = [] frontier = set(seed_nodes) for hop in range(max_hops): if len(contexts) >= max_contexts: break next_frontier: set[str] = set() for node in frontier: for _, neighbor, data in G.edges(node, data=True): chunk_id = data.get("chunk_id", "") relation = data.get("relation", "") if chunk_id and chunk_id not in seen_chunks: seen_chunks.add(chunk_id) result = collection.get(ids=[chunk_id], include=["documents"]) if result["documents"]: contexts.append(Context( text=result["documents"][0], source="graph", score=1.0 / (hop + 1), # closer hops = higher score path=f"{node} -[{relation}]→ {neighbor}", )) next_frontier.add(neighbor) frontier = next_frontier return contexts[:max_contexts]
Cap max_hops at 2-3. Each additional hop multiplies the number of nodes traversed exponentially in a dense graph. With max_hops=5 on a graph with 500 nodes, a single query can trigger thousands of ChromaDB get() calls. The default of 2 is sufficient for most multi-hop questions in practice.
🌐FastAPI Endpoints
knowledge_graph.json. Slow (~2-5 s per chunk). Run once after initial document ingestion.source: "vector" or source: "graph" with the graph traversal path).knowledge_graph.json. Next POST /graph/build starts from scratch. Use when you've re-chunked your documents and want a clean rebuild.@router.get("/query", response_model=QueryResponse) async def graph_query( q: Annotated[str, Query(description="Question")], tenant_id: Annotated[str, Query()] = "default", vector_k: Annotated[int, Query(ge=1, le=10)] = 4, graph_k: Annotated[int, Query(ge=0, le=6)] = 3, max_hops: Annotated[int, Query(ge=1, le=3)] = 2, ): collection = _get_collection(tenant_id) G = gb.load() contexts = gr.retrieve( question=q, collection=collection, G=G, model=_GEN_MODEL, vector_k=vector_k, graph_k=graph_k, max_hops=max_hops, ) # Tag each context with its source so the LLM knows which are graph-derived context_block = "\n\n".join( f"[{c.source.upper()}]{' via ' + c.path if c.path else ''}\n{c.text}" for c in contexts ) resp = ollama.chat( model=_GEN_MODEL, messages=[ {"role": "system", "content": _SYSTEM_PROMPT}, {"role": "user", "content": f"Context:\n{context_block}\n\nQuestion: {q}"}, ], options={"temperature": 0, "num_predict": 512}, ) return QueryResponse( answer=resp["message"]["content"].strip(), contexts=[{"text": c.text, "source": c.source, "score": c.score, "path": c.path} for c in contexts], )
🚀Running Multi-Hop Queries
Step-by-step workflow
curl -X POST http://localhost:8000/graph/build \ -H 'Content-Type: application/json' \ -d '{"tenant_id": "default", "model": "llama3.2:3b"}' # Response: {"nodes": 142, "edges": 389, "chunks_processed": 47}
curl "http://localhost:8000/graph/query?q=Which+company+did+the+CEO+of+Acme+Corp+found%3F&tenant_id=default" # Response: { "answer": "Alice Lee, the CEO of Acme Corp, co-founded DataBridge in 2019.", "contexts": [ { "text": "Alice Lee co-founded DataBridge in 2019...", "source": "graph", "score": 0.5, "path": "alice lee -[co-founded]→ databrige" }, { "text": "Alice Lee is the CEO of Acme Corp...", "source": "vector", "score": 0.871, "path": "" } ] }
When to use each retrieval mode
| Question type | Vector RAG | GraphRAG (hybrid) |
|---|---|---|
| Single-hop "What does X do?" |
Excellent - direct semantic match, fast, no graph needed | Works equally well; slight overhead from entity extraction + graph lookup |
| Multi-hop "Who founded the company led by X?" |
Often fails - the linking chunk has no similarity to the question | Works - traverses the entity chain from X through CEO-of to company to founder |
| Aggregation "List all products by X" |
Partial - retrieves the most similar chunks, may miss some | Better - all edges from node X are traversed, more complete coverage |
| Abstract/conceptual "Explain the difference between A and B" |
Good - embedding similarity captures conceptual questions well | Graph adds little here; graph_k=0 disables graph traversal for these |
POST /graph/build once after initial ingestion, and again only when new documents are added. The knowledge_graph.json file persists across restarts - it's loaded at query time, not rebuilt. Mount it as a volume in Docker or K8s so it survives pod restarts.From similarity to structure
You've added a second retrieval dimension to the Article 3 RAG API. Vector search finds what's similar; the knowledge graph finds what's connected. Together they handle the full range of question types - including multi-hop reasoning that purely embedding-based systems consistently fail at.
The next article goes deeper into graph querying: natural language to Cypher - converting free-text questions into structured graph queries so you can retrieve precise sub-graphs, not just BFS neighborhoods.
Article 7 → Agentic RAG - ReAct Agent with Tool-Calling →