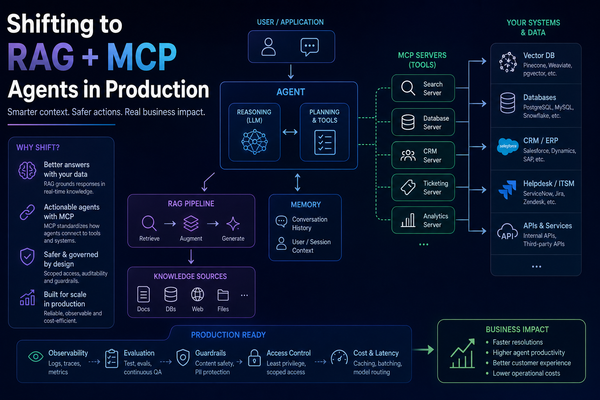
3. Multi-Tenant Document Q&A API
Build a multi-tenant RAG API where each tenant's documents are fully isolated. FastAPI, per-tenant ChromaDB collections, JWT authentication, and a clean REST interface for document ingestion and querying.


Multi-Tenant Document Q&A
FastAPI + ChromaDB
Build a production-ready REST API where every user has an isolated document collection - FastAPI, ChromaDB namespaces, JWT auth, and a local Llama 3.2 model via Ollama. Zero paid APIs, zero cloud dependencies.
🎯What You'll Build
Articles 1 and 2 built single-user command-line tools. This article builds a multi-user REST API - the shape that most production RAG applications take in practice. Each registered user gets a completely isolated document namespace: they can upload their own files, ask questions about their own content, and never see another user's data.
The API is fully local and open-source. Embeddings are computed by sentence-transformers running on your CPU. The LLM is Llama 3.2:3b served by Ollama - downloaded once to disk, runs entirely offline. No OpenAI account, no API credits, no internet connection required after setup.
By the end of this article you will have a running API with five endpoints, an interactive Swagger UI at /docs, SQLite persistence for user and document metadata, and ChromaDB collections that are isolated at the database level - not just filtered at query time.
ollama pull llama3.2:3b🏛️Architecture & Tenant Isolation
The system has three storage layers, each serving a different purpose:
tenant_<user_id>. The tenant's vector space is physically separate from every other tenant's.~/.ollama/models/) after the first ollama pull. Subsequent starts are instant - no re-download.Why one collection per tenant?
The alternative approach - one shared collection with a tenant_id metadata filter - is simpler to set up but has two serious problems in production. First, it means a misconfigured filter silently returns another user's documents instead of returning nothing. The failure mode is a data leak, not an error. Second, ChromaDB (and most vector databases) must scan all vectors and filter post-hoc, which means query latency scales with the total number of users rather than with the individual tenant's corpus size.
- -Query scans ALL tenants' vectors, filters by metadata
- -Latency grows with total user count, not tenant corpus size
- -A filter bug leaks another user's data - silent failure
- -Deleting a user requires scanning and deleting individual docs
- +Query scans only the authenticated user's vectors
- +Latency scales with tenant corpus - independent of other users
- +A code bug returns empty results, never another user's data
- +Deleting a user =
client.delete_collection(name)- one call
The request flow for a query is:
🧰Technology Stack
Every component in this stack is free, open source, and runs locally. You do not need an OpenAI account, an AWS account, or any subscription. The only internet connection needed is for the one-time pip install and ollama pull.
FastAPI 0.115.6
Async-capable Python web framework with automatic OpenAPI documentation, Pydantic v2 integration, and dependency injection. The Depends() system is how we wire JWT auth into every protected route.
ChromaDB 0.5.18
Embedded vector database with per-collection isolation. One get_or_create_collection("tenant_<id>") call per user - no schema migrations, no DDL, no separate process.
Ollama + Llama 3.2:3b
Ollama is an open-source LLM runner. Llama 3.2:3b is Meta's 3-billion-parameter model - fast enough on CPU for interactive responses (~2-8 seconds per query). Swap for llama3.1:8b for higher quality.
sentence-transformers 3.3.1
Same model as Articles 1 and 2: all-MiniLM-L6-v2, 384 dimensions, ~5ms per batch on CPU. Loaded once at startup via the lifespan hook.
SQLAlchemy 2.0 + SQLite
SQLAlchemy 2.0-style ORM with Mapped[] typed columns. SQLite requires zero setup - the database is a single file (rag_api.db) created automatically on first start.
python-jose + passlib[bcrypt]
JWT creation and verification with python-jose. Password hashing with bcrypt via passlib. Both are pure Python with no external service dependency.
📁Project Setup & Directory Structure
Ollama setup (one-time)
# Install Ollama (Linux / macOS) curl -fsSL https://ollama.com/install.sh | sh # Pull Llama 3.2:3b - ~2 GB, downloaded once to ~/.ollama/models/ ollama pull llama3.2:3b # Verify it works (optional) ollama run llama3.2:3b "Explain RAG in one sentence." # Keep Ollama running in the background for the API to use ollama serve # or it starts automatically on most Linux installs
llama3.2:3b - fastest, ~2 GB, good for testing. llama3.1:8b - better quality, ~5 GB, needs ~8 GB RAM. mistral:7b - alternative architecture, similar quality to 8b. phi3:mini - Microsoft's 3.8B model, very fast. All are free to pull via Ollama. Change OLLAMA_MODEL in your .env to switch.
Python setup
python3.11 -m venv .venv source .venv/bin/activate pip install -r requirements.txt cp env.example .env
Directory layout
article-03/ ├── main.py # FastAPI app, lifespan, CORS ├── config.py # Pydantic Settings (reads .env) ├── database.py # SQLAlchemy models + session factory ├── auth.py # JWT creation/verification + get_current_user dep ├── schemas.py # Pydantic request/response schemas ├── embedder.py # sentence-transformers singleton ├── vectorstore.py # ChromaDB per-tenant collection manager ├── ingestor.py # text → chunks → ChromaDB ├── llm.py # Ollama client wrapper ├── routers/ │ ├── auth.py # POST /auth/register POST /auth/login │ ├── documents.py # POST /documents/ GET /documents/ DELETE /documents/{id} │ └── query.py # POST /query/ ├── requirements.txt └── env.example
🗄️Data Layer - SQLAlchemy 2.0
The database layer has two tables. Users stores accounts; Documents stores metadata about uploaded files. The actual text content and embeddings live in ChromaDB - the SQL database only records that a document exists and how many chunks it produced.
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship from sqlalchemy import DateTime, ForeignKey, Integer, String class Base(DeclarativeBase): pass class User(Base): __tablename__ = "users" id: Mapped[str] = mapped_column(String(36), primary_key=True, default=lambda: str(uuid.uuid4())) email: Mapped[str] = mapped_column(String(255), unique=True, index=True) hashed_password: Mapped[str] = mapped_column(String(255)) created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True)) documents: Mapped[list["Document"]] = relationship( back_populates="owner", cascade="all, delete-orphan" ) class Document(Base): __tablename__ = "documents" id: Mapped[str] = mapped_column(String(36), primary_key=True, ...) tenant_id: Mapped[str] = mapped_column(ForeignKey("users.id", ondelete="CASCADE")) filename: Mapped[str] = mapped_column(String(255)) chunk_count: Mapped[int] = mapped_column(Integer, default=0) created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True))
Several design decisions worth noting here:
str(uuid.uuid4())) instead of auto-increment integers. UUIDs are safe to expose in URLs and in JWT payloads because they are not guessable - an attacker cannot try /documents/1, /documents/2, etc. to enumerate records.ForeignKey("users.id", ondelete="CASCADE") on tenant_id means that deleting a user row automatically deletes all their document rows at the database level - no application-level cascade logic needed. The ChromaDB collection still requires explicit cleanup via delete_tenant_collection().chunk_count column stores how many chunks a document produced, but the chunks themselves live only in ChromaDB. This means SQL is the authority on document existence, and ChromaDB is the authority on searchable content - they can be independently backed up, scaled, or replaced.The session dependency follows the FastAPI pattern - a generator that opens a session before the request and closes it after, whether the request succeeded or raised an exception:
def get_db() -> Generator[Session, None, None]: db = SessionLocal() try: yield db finally: db.close() # always runs - even if the route raised an exception
🔐Auth Layer - JWT & bcrypt
Authentication uses industry-standard components: bcrypt for password hashing and JWT (JSON Web Tokens) for session management. There is no session store, no Redis - the token itself contains the user's ID.
Password hashing
Passwords are hashed with bcrypt via passlib. bcrypt is deliberately slow - it performs 2^cost iterations by default. This means brute-forcing a bcrypt hash requires orders of magnitude more compute than MD5 or SHA-256. We never store plain-text passwords anywhere - not in logs, not in database columns, not in error messages.
_pwd_ctx = CryptContext(schemes=["bcrypt"], deprecated="auto") def hash_password(plain: str) -> str: return _pwd_ctx.hash(plain) # "$2b$12$..." - bcrypt output def verify_password(plain: str, hashed: str) -> bool: return _pwd_ctx.verify(plain, hashed) # constant-time comparison
JWT flow
On login, we create a JWT containing the user's ID (sub claim) and an expiry timestamp (exp claim). The client stores this token and sends it as a Authorization: Bearer <token> header on every subsequent request.
def create_access_token(user_id: str) -> str: expire = datetime.now(tz=timezone.utc) + timedelta(hours=settings.jwt_expire_hours) return jwt.encode( {"sub": user_id, "exp": expire}, settings.jwt_secret_key, algorithm=settings.jwt_algorithm, ) def get_current_user( credentials: HTTPAuthorizationCredentials = Depends(_bearer), db: Session = Depends(get_db), ) -> User: """ FastAPI dependency injected into every protected route. 1. Extracts Bearer token from Authorization header 2. Decodes and validates JWT signature + expiry 3. Loads User row from SQLite - raises 404 if deleted """ user_id = _decode_token(credentials.credentials) # raises 401 if invalid user = db.get(User, user_id) if not user: raise HTTPException(status_code=404, detail="User not found.") return user
The get_current_user dependency is injected via Depends() into any route that requires authentication. FastAPI resolves all dependencies before calling the route function - if JWT validation fails, the route function is never called at all.
The JWT_SECRET_KEY is used to sign and verify all tokens. Anyone who knows this value can forge valid tokens for any user ID. Generate it with python -c "import secrets; print(secrets.token_hex(32))" and store it in your .env file. Never commit the real value to version control.
🗂️Vector Layer - ChromaDB per Tenant
The vectorstore.py module owns all ChromaDB interactions. It is the only file that imports chromadb - a deliberate choice that makes it trivial to swap ChromaDB for another vector database later without touching any router code.
Collection naming convention
Each user's collection is named tenant_<user_id_with_underscores>. We replace hyphens with underscores because ChromaDB collection names must match the regex [a-zA-Z0-9_-] and must not start with a number - replacing hyphens in UUIDs is the safest normalisation.
def _collection_name(tenant_id: str) -> str: return f"tenant_{tenant_id.replace('-', '_')}" # e.g. "tenant_550e8400_e29b_41d4_a716_446655440000" def add_chunks(tenant_id: str, doc_id: str, chunks: list[str]) -> int: collection = get_or_create_collection(tenant_id) embeddings = embed_texts(chunks).tolist() ids = [f"{doc_id}:{i}" for i in range(len(chunks))] metadatas = [{"doc_id": doc_id, "chunk_index": i} for i in range(len(chunks))] collection.upsert(ids=ids, documents=chunks, embeddings=embeddings, metadatas=metadatas) return len(chunks) def search_chunks(tenant_id: str, query: str, k: int = 4, doc_id: str | None = None) -> list[dict]: collection = get_or_create_collection(tenant_id) if collection.count() == 0: return [] where = {"doc_id": doc_id} if doc_id else None results = collection.query( query_embeddings=embed_texts([query]).tolist(), n_results=min(k, collection.count()), where=where, include=["documents", "metadatas", "distances"], ) return [ {"text": t, "doc_id": m["doc_id"], "chunk_index": m["chunk_index"], "distance": d} for t, m, d in zip(results["documents"][0], results["metadatas"][0], results["distances"][0]) ]
The optional doc_id filter in search_chunks() enables per-document queries - a user can ask a question about a specific uploaded file rather than all of their documents. This is implemented as a ChromaDB where clause, which is a post-retrieval metadata filter within the already-isolated tenant collection.
Document ID strategy for upserts
Chunk IDs follow the format <doc_id>:<chunk_index> and are submitted to ChromaDB via upsert(). This means uploading the same document twice does not create duplicate chunks - the second upload overwrites the first. This is intentional: it makes re-ingestion idempotent, which is useful when a user wants to re-process a document with different chunking settings.
🔌API Layer - FastAPI Routers
The API is split into three routers, each in its own file. All routes that touch documents or queries are protected - they require a valid Bearer JWT in the Authorization header.
Endpoints overview
{"email": "...", "password": "..."} (password ≥ 8 chars). Returns the new user object. Raises 409 if email is already registered.{"email": "...", "password": "..."}. Returns {"access_token": "eyJ...", "token_type": "bearer"}. Raises 401 on bad credentials..txt or .md file (max 10 MB). Requires Bearer token. The file is read, split into chunks, embedded, and stored in the authenticated user's ChromaDB collection. Returns DocumentResponse with chunk_count.list[DocumentResponse].{"question": "...", "top_k": 4, "doc_id": null}. Retrieves top-k passages from ChromaDB, passes them to Ollama, returns a grounded QueryResponse with answer and sources.The upload route in detail
The document upload route demonstrates a critical pattern: write metadata to SQL first, then index into ChromaDB, and roll back the SQL row if indexing fails. This keeps the two storage layers consistent:
# 1. Persist metadata first (so we have a doc_id for ChromaDB) doc = Document(tenant_id=current_user.id, filename=file.filename, chunk_count=0) db.add(doc); db.commit(); db.refresh(doc) try: # 2. Embed + index (can fail: OOM, Chroma error, …) n = ingest_text(text=text, tenant_id=current_user.id, doc_id=doc.id) doc.chunk_count = n db.commit() except Exception as exc: # 3. Remove the orphan SQL row if indexing failed db.delete(doc); db.commit() raise HTTPException(status_code=500, detail=f"Ingestion failed: {exc}")
The LLM call
In llm.py, the Ollama call uses the official ollama Python package - not an HTTP client, not the OpenAI compatibility layer. The options={"temperature": 0} setting makes the model deterministic: the same question with the same context will always produce the same answer, which is essential for testing.
response = ollama.chat( model=settings.ollama_model, # "llama3.2:3b" from .env messages=[{"role": "user", "content": prompt}], options={"temperature": 0, "num_predict": 512}, ) return response["message"]["content"].strip()
Starting the server
# Make sure Ollama is running in another terminal: # ollama serve # Start the API uvicorn main:app --reload --port 8000 # On startup you'll see: # Starting up - initialising database … # Pre-loading embedding model … # Application ready. # Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) # Open Swagger UI in your browser: # http://localhost:8000/docs
🧪Testing with curl & HTTPie
The full workflow - register, login, upload, query, delete - in curl commands:
# 1. Register curl -s -X POST http://localhost:8000/auth/register \ -H "Content-Type: application/json" \ -d '{"email":"alice@example.com","password":"s3cur3p4ss"}' # {"id":"550e8400-...","email":"alice@example.com","created_at":"..."} # 2. Login - save token TOKEN=$(curl -s -X POST http://localhost:8000/auth/login \ -H "Content-Type: application/json" \ -d '{"email":"alice@example.com","password":"s3cur3p4ss"}' \ | python3 -c "import sys,json; print(json.load(sys.stdin)['access_token'])") # 3. Upload a text file curl -s -X POST http://localhost:8000/documents/ \ -H "Authorization: Bearer $TOKEN" \ -F "file=@my_document.txt" # {"document":{"id":"...","filename":"my_document.txt","chunk_count":42,...}} # 4. List documents curl -s http://localhost:8000/documents/ \ -H "Authorization: Bearer $TOKEN" # 5. Ask a question (searches ALL uploaded documents) curl -s -X POST http://localhost:8000/query/ \ -H "Authorization: Bearer $TOKEN" \ -H "Content-Type: application/json" \ -d '{"question":"What is the main conclusion?","top_k":4}' # {"question":"...","answer":"Based on the provided context...","sources":[...]} # 6. Ask about a specific document only curl -s -X POST http://localhost:8000/query/ \ -H "Authorization: Bearer $TOKEN" \ -H "Content-Type: application/json" \ -d '{"question":"...","doc_id":"<document_id_from_step_3>","top_k":4}' # 7. Delete a document curl -s -X DELETE http://localhost:8000/documents/<doc_id> \ -H "Authorization: Bearer $TOKEN"
The Swagger UI at http://localhost:8000/docs provides an interactive alternative - click "Authorize", paste your token, and you can call every endpoint directly from the browser without writing any curl commands.
To verify the isolation is working: create two accounts (alice and bob), upload different documents to each, then query from alice's token. You should never see bob's content in the results. The structural guarantee is in vectorstore.py: search_chunks(tenant_id=current_user.id, ...) hardcodes the tenant to the authenticated user - there is no path in the code where a different tenant's collection is queried.
🚀Production Checklist
env.example ships with JWT_SECRET_KEY=changeme-generate-a-real-secret-for-production. Any developer who reads the open-source code knows this default and can forge tokens for any user_id in your database.python -c "import secrets; print(secrets.token_hex(32))". Rotate it if the .env file is ever accidentally committed.database is locked errors. SQLite serialises all writes, which becomes a bottleneck above ~50 req/s.DATABASE_URL to a PostgreSQL URL (postgresql://user:pass@host:5432/rag) and add psycopg2 or asyncpg to requirements. The SQLAlchemy models require zero changes - only the engine URL changes.uvicorn --workers 4 spawns 4 processes, all trying to write to the same .chroma/ directory - this causes data corruption.chromadb.HttpClient pointing at a dedicated Chroma server container (docker run -p 8001:8001 chromadb/chroma). Change one line in vectorstore.py - no other file changes required.GET /query/{job_id}/result polling endpoint. Alternatively, switch to a GPU-backed model server (vLLM, TGI) for true concurrency.Production decision tree
llama3.2:3b (~2s/query on CPU). Production quality → llama3.1:8b or mixtral:8x7b (~8-30s on CPU, <1s on GPU). Best open-source → llama3.1:70b via Ollama on a GPU machine.python-docx + openpyxl pre-processing step before ingestor.ollama.chat(stream=True) with FastAPI's StreamingResponse and server-sent events. Token-by-token output begins appearing immediately instead of after the full 2-8 second generation.A complete multi-tenant RAG backend - zero paid APIs.
You have built a production-shaped REST API: JWT authentication, per-tenant ChromaDB isolation, a local Llama 3.2 model via Ollama, and a rollback-safe upload flow. Every piece is free, open source, and runs on your laptop.
The next article in the series adds streaming responses, rate limiting, and a React chat frontend - turning this backend into a complete, deployable AI product.
→ Article 4: Streaming RAG Chat with a React Frontend