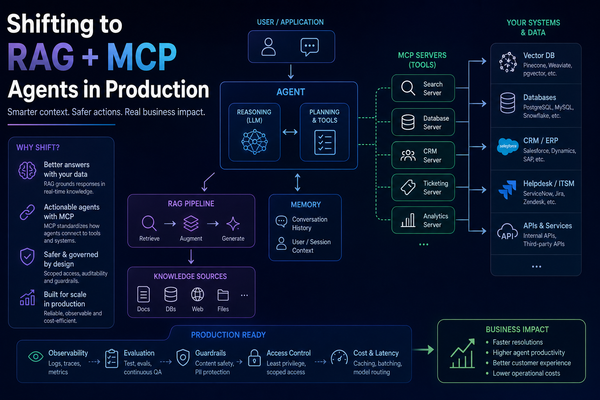
5. Evaluating RAG Quality with RAGAS
Stop guessing whether your RAG pipeline is good. Use RAGAS to measure faithfulness, answer relevancy, context precision and recall — and learn to interpret the metrics to drive concrete improvements.


Evaluating RAG Quality
with RAGAS
Your demo works. But how do you know it's actually answering correctly? This article adds automated evaluation: faithfulness, relevance, and context scoring - entirely with local Ollama models, no paid APIs.
🎯The Evaluation Gap
You've shipped a RAG pipeline. Documents are uploaded, questions are answered, the demo looks convincing. But there's a gap between looks correct and is correct.
Without metrics, every change to your retrieval strategy, embedding model, chunking size, or prompt is a guess. You tune chunk size from 512 to 256 tokens - does retrieval improve? You switch from llama3.2:3b to mistral:7b for generation - are answers more faithful to the documents? You can't know without measuring.
What developers usually do
- Ask a few questions manually and check the answers
- Use "vibes" - it feels better after the change
- Ship and wait for user complaints
- No baseline, no regression detection
What we'll build instead
- A synthetic test dataset from your own documents
- 4 RAGAS metrics computed entirely with local Ollama models
- FastAPI endpoints to trigger runs and retrieve scores
- A standalone CI script that fails below a threshold
RAGAS stands for Retrieval Augmented Generation Assessment. The key insight is that evaluation itself can be automated with an LLM acting as a judge - comparing answers against retrieved contexts and ground truth without any human in the loop. This makes it feasible to run eval after every code change.
📐RAGAS Metrics Explained
RAGAS measures four distinct failure modes in a RAG pipeline. Each metric probes a different part of the system. Understanding what each one measures tells you which component to fix when a score is low.
How each metric is computed
Answer vs. Contexts
The judge LLM breaks the answer into individual claims, then checks each claim against the retrieved contexts. Score = supported claims ÷ total claims. Catches hallucinations - claims the model invented from training data rather than the documents.
Answer vs. Question
The LLM generates N "reverse questions" from the answer. These are embedded alongside the original question. Score = average cosine similarity. Catches verbose or off-topic answers that are technically correct but don't address the question.
Retrieval ranking
For each retrieved chunk, the judge decides whether it genuinely helps answer the question. Score rewards useful chunks that appear in higher positions. A low score means irrelevant chunks are crowding out the useful ones - check your retrieval ranking.
Coverage of ground truth
Each sentence of the ground truth answer is checked against retrieved contexts. Score = sentences supported ÷ total sentences. Requires ground_truth in the dataset. A low score means important chunks weren't retrieved - check your chunking or top_k.
Judge model quality matters. RAGAS calls the judge LLM dozens of times per sample to extract claims, verify them, and generate reverse questions. A model that can't follow structured instructions (like llama3.2:1b) will produce unreliable scores. Use at least a 7B model: mistral:7b or llama3.1:8b consistently work well as judges.
🏗Architecture Overview
This article adds an evaluation layer on top of the Article 3 multi-tenant RAG API. The evaluation pipeline is separate from the serving path - it runs offline and never touches the live query flow.
The pipeline runs in two phases. First, dataset building: sample random chunks from ChromaDB, generate QA pairs with a generator LLM, query the RAG pipeline for actual answers, and save everything to eval_dataset.json. Second, evaluation: load the dataset, send each sample to RAGAS using a judge LLM, and collect the four metric scores.
The two phases are decoupled deliberately. Building the dataset is slow (Ollama calls per chunk) and only needs to run when your document corpus changes. Running RAGAS is also slow (judge LLM calls per sample) but can be re-run independently whenever you change the pipeline code.
🧰Technology Stack
RAGAS 0.2
Open-source RAG evaluation framework. The 0.2 API uses EvaluationDataset and SingleTurnSample instead of the legacy HuggingFace Dataset format. Supports pluggable LLM backends via LangChain wrappers.
langchain-ollama
Thin LangChain integration for Ollama. Provides ChatOllama and OllamaEmbeddings - both needed by RAGAS. No OpenAI key, no external API calls. Everything stays on localhost:11434.
mistral:7b (judge)
Used exclusively for evaluation, not for serving answers. Mistral 7B reliably follows structured evaluation instructions and produces consistent verdicts. You can swap it for llama3.1:8b - both work well.
nomic-embed-text
Used by RAGAS for the Answer Relevancy metric (cosine similarity between question and reverse-questions). 137M parameters, fast on CPU, same model already pulled for Article 3's retrieval.
Two Ollama models are needed simultaneously during evaluation. Pull them before running: ollama pull mistral:7b and ollama pull nomic-embed-text. The generator model (llama3.2:3b) for the RAG answers should already be running from Article 3.
⚙️Project Setup
Article 5 builds directly on the Article 3 codebase (multi-tenant RAG API). Add the new dependencies to the existing requirements.txt:
# Existing Article 3 deps: fastapi, uvicorn, chromadb, ollama, … # Article 5 additions ragas==0.2.15 langchain-ollama==0.2.3 langchain-core==0.3.63 datasets==3.6.0
Install with pip:
pip install ragas==0.2.15 langchain-ollama==0.2.3 langchain-core==0.3.63 datasets==3.6.0
Pull the two Ollama models needed for evaluation:
# Judge LLM - used for Faithfulness, Context Precision, Context Recall ollama pull mistral:7b # Embedding model - used for Answer Relevancy ollama pull nomic-embed-text # Generator model - already from Article 3 ollama pull llama3.2:3b
The final project layout, combining Article 3 files with the new eval additions:
project/ ├── main.py # Article 3 - add eval router here ├── config.py # Article 3 ├── requirements.txt ├── eval_dataset.py # NEW - dataset builder ├── evaluator.py # NEW - RAGAS runner ├── run_eval.py # NEW - standalone CI script ├── eval_dataset.json # generated, git-ignored ├── eval_results.json # generated, git-ignored └── routers/ ├── documents.py # Article 3 ├── query.py # Article 3 └── eval.py # NEW - eval endpoints
Add eval_dataset.json and eval_results.json to your .gitignore. These files contain your document content (in the QA pairs) and evaluation scores - neither belongs in version control. The scripts that generate them are what you commit.
🗂Building a Test Dataset
A RAGAS evaluation needs a dataset of (question, answer, contexts, ground_truth) tuples. The approach here is fully synthetic: sample random chunks from ChromaDB, ask Ollama to generate a question+correct answer from each chunk, then feed the question back through the live RAG pipeline to get the actual answer and retrieved contexts.
This is the self-consistency approach: the ground truth comes from the source documents themselves, so no human labeling is required.
from __future__ import annotations import json, logging, random from dataclasses import dataclass, asdict from pathlib import Path import chromadb import ollama log = logging.getLogger(__name__) DATASET_PATH = Path("eval_dataset.json") _GENERATOR_MODEL = "llama3.2:3b" _QA_PROMPT = """\ Given the text below, write exactly ONE clear factual question whose answer is fully contained in the text. Reply ONLY with valid JSON on one line: {{"question": "...", "answer": "..."}} Text: {chunk}""" @dataclass class EvalSample: question: str answer: str # RAG pipeline answer contexts: list[str] # retrieved contexts ground_truth: str # correct answer from source chunk def _generate_qa(chunk: str) -> tuple[str, str] | None: """Ask the generator LLM to produce a (question, ground_truth) pair.""" try: resp = ollama.chat( model=_GENERATOR_MODEL, messages=[{"role": "user", "content": _QA_PROMPT.format(chunk=chunk)}], options={"temperature": 0.3, "num_predict": 256}, ) raw = resp["message"]["content"].strip() # strip markdown fences if the model wrapped the JSON if raw.startswith("```"): raw = raw.split("```")[1].lstrip("json").strip() data = json.loads(raw) return data["question"], data["answer"] except (json.JSONDecodeError, KeyError) as exc: log.warning("QA generation failed: %s", exc) return None def _rag_query( question: str, collection: chromadb.Collection, rag_model: str, top_k: int = 4, ) -> tuple[str, list[str]]: """Run the RAG pipeline and return (answer, contexts).""" results = collection.query( query_texts=[question], n_results=top_k, include=["documents"] ) contexts: list[str] = results["documents"][0] resp = ollama.chat( model=rag_model, messages=[ {"role": "system", "content": ( "Answer using ONLY the provided context. " "If not in context, say 'I don't know'." )}, {"role": "user", "content": ( "Context:\n" + "\n---\n".join(contexts) + f"\n\nQuestion: {question}" )}, ], options={"temperature": 0, "num_predict": 512}, ) return resp["message"]["content"].strip(), contexts def build( tenant_id: str = "default", n_samples: int = 20, chroma_host: str = "http://localhost:8001", rag_model: str = "llama3.2:3b", ) -> list[EvalSample]: """Build a RAGAS evaluation dataset from the ChromaDB corpus.""" host, port = chroma_host.split("://")[1].rsplit(":", 1) client = chromadb.HttpClient(host=host, port=int(port)) collection = client.get_collection(f"tenant_{tenant_id}") total = collection.count() indices = random.sample(range(total), min(n_samples, total)) all_chunks = collection.get( ids=[str(i) for i in indices], include=["documents"] )["documents"] samples: list[EvalSample] = [] for i, chunk in enumerate(all_chunks, 1): qa = _generate_qa(chunk) if qa is None: continue question, ground_truth = qa log.info("[%d/%d] %s", i, len(all_chunks), question[:70]) answer, contexts = _rag_query(question, collection, rag_model) samples.append(EvalSample( question=question, answer=answer, contexts=contexts, ground_truth=ground_truth, )) DATASET_PATH.write_text(json.dumps([asdict(s) for s in samples], indent=2)) log.info("Saved %d samples → %s", len(samples), DATASET_PATH) return samples def load(path: Path = DATASET_PATH) -> list[EvalSample]: return [EvalSample(**d) for d in json.loads(path.read_text())]
What a completed sample looks like
{
"question": "What database does the multi-tenant RAG API use for vector storage?",
"answer": "The API uses ChromaDB for vector storage, with one collection per tenant.",
"contexts": [
"ChromaDB is used as the vector store. Each tenant gets an isolated collection...",
"Documents are chunked at 512 tokens with 64-token overlap before embedding..."
],
"ground_truth": "ChromaDB is used for vector storage with per-tenant collections."
}
[str(i) for i in range(n)] and expect them to exist - the actual IDs depend on how documents were inserted. Calling collection.get() without IDs returns all documents. Sample from the returned list instead.collection.get(include=["documents"]) to retrieve all docs, then random.sample(documents, n) from the returned list. This works regardless of how IDs were assigned during insertion.🔌Configuring RAGAS with Ollama
RAGAS 0.2 ships without any LLM vendor built in. Instead, it accepts any LangChain-compatible LLM and embeddings object. The wiring is three lines:
from langchain_ollama import ChatOllama, OllamaEmbeddings from ragas.llms import LangchainLLMWrapper from ragas.embeddings import LangchainEmbeddingsWrapper # Judge LLM - used for Faithfulness, ContextPrecision, ContextRecall llm = LangchainLLMWrapper( ChatOllama(model="mistral:7b", base_url="http://localhost:11434", temperature=0) ) # Embedding model - used for AnswerRelevancy (cosine similarity) embeddings = LangchainEmbeddingsWrapper( OllamaEmbeddings(model="nomic-embed-text", base_url="http://localhost:11434") )
RAGAS uses these objects to make dozens of LLM calls per sample. For Faithfulness alone, it calls the judge once to decompose the answer into claims, then once per claim to verify it against contexts. With 20 samples and 3 claims per answer on average, that's ~60 judge calls just for Faithfulness. Budget 10-20 minutes for a full evaluation run with a local 7B model.
Metrics using the judge LLM
- Faithfulness - claim extraction + verification
- Context Precision - relevance verdicts per chunk
- Context Recall - coverage of ground truth sentences
Metrics using embeddings
- Answer Relevancy - reverse question generation (LLM) + embedding similarity
- Requires both
llmandembeddingsto be set
Set temperature=0 on the judge model. RAGAS expects deterministic, structured outputs (JSON verdicts, numbered claim lists). A non-zero temperature introduces noise into the judge's answers, making scores irreproducible across runs. This doesn't apply to the generator model used for building the dataset - variation there is fine.
⚡The Evaluation Pipeline
With the Ollama models wired up, evaluator.py converts the flat EvalSample list into RAGAS's EvaluationDataset format, runs the four metrics, and returns typed results:
from dataclasses import dataclass, asdict from langchain_ollama import ChatOllama, OllamaEmbeddings from ragas import EvaluationDataset, SingleTurnSample, evaluate from ragas.embeddings import LangchainEmbeddingsWrapper from ragas.llms import LangchainLLMWrapper from ragas.metrics import ( AnswerRelevancy, ContextPrecision, ContextRecall, Faithfulness, ) from eval_dataset import EvalSample _OLLAMA_BASE = "http://localhost:11434" @dataclass class EvalResult: faithfulness: float answer_relevancy: float context_precision: float context_recall: float num_samples: int def dict(self) -> dict: return asdict(self) def run( samples: list[EvalSample], judge_model: str = "mistral:7b", embed_model: str = "nomic-embed-text", ) -> EvalResult: llm = LangchainLLMWrapper( ChatOllama(model=judge_model, base_url=_OLLAMA_BASE, temperature=0) ) embeddings = LangchainEmbeddingsWrapper( OllamaEmbeddings(model=embed_model, base_url=_OLLAMA_BASE) ) dataset = EvaluationDataset(samples=[ SingleTurnSample( user_input=s.question, response=s.answer, retrieved_contexts=s.contexts, reference=s.ground_truth, ) for s in samples ]) result = evaluate( dataset=dataset, metrics=[Faithfulness(), AnswerRelevancy(), ContextPrecision(), ContextRecall()], llm=llm, embeddings=embeddings, ) return EvalResult( faithfulness= round(float(result["faithfulness"]), 4), answer_relevancy= round(float(result["answer_relevancy"]), 4), context_precision= round(float(result["context_precision"]), 4), context_recall= round(float(result["context_recall"]), 4), num_samples=len(samples), )
Running it from the command line
# Build dataset (20 QA pairs from tenant "default") then run RAGAS python run_eval.py --tenant default --samples 20 # Build dataset only - skip evaluation for now python run_eval.py --dataset-only # Re-run evaluation on existing dataset (faster iteration) python run_eval.py --eval-only --judge-model llama3.1:8b # Fail with exit code 1 if any metric drops below 0.7 python run_eval.py --fail-below 0.7
The script prints a formatted result table:
── RAGAS Evaluation Results ────────────────────────────────── ✓ Faithfulness 0.831 [████████████████░░░░] (threshold 0.7) ✓ Answer Relevancy 0.784 [███████████████░░░░░] (threshold 0.7) ✗ Context Precision 0.612 [████████████░░░░░░░░] (threshold 0.6) ✓ Context Recall 0.756 [███████████████░░░░░] (threshold 0.6) Samples evaluated: 20 ──────────────────────────────────────────────────────────────
🌐FastAPI Eval Endpoints
Add three endpoints so the evaluation pipeline can be triggered over HTTP - useful for scheduled jobs, admin dashboards, or integration into a CI webhook.
Wire the eval router into the existing Article 3 main.py:
from routers import documents, query, eval # add eval app.include_router(eval.router) # add this line
The three eval endpoints:
tenant_id, n_samples, rag_model. Returns HTTP 202 immediately - check logs for completion.judge_model, embed_model. Returns the four metric scores. Note: this can take 10-20 minutes - consider bumping your HTTP client timeout.eval_results.json. Instant - reads from disk.from fastapi import APIRouter, BackgroundTasks, HTTPException, status from pydantic import BaseModel, Field import eval_dataset as ds import evaluator as ev router = APIRouter(prefix="/eval", tags=["eval"]) class RunRequest(BaseModel): judge_model: str = Field("mistral:7b") embed_model: str = Field("nomic-embed-text") @router.post("/run", response_model=ResultsResponse) async def run_evaluation(body: RunRequest): if not ds.DATASET_PATH.exists(): raise HTTPException( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail="No dataset. Call POST /eval/dataset first.", ) samples = ds.load() result = ev.run(samples, judge_model=body.judge_model, embed_model=body.embed_model) _save_results(result) payload = result.dict() payload["evaluated_at"] = datetime.now(timezone.utc).isoformat() return payload @router.get("/results", response_model=ResultsResponse) async def get_results(): if not _RESULTS_PATH.exists(): raise HTTPException(status_code=404, detail="No results yet.") return json.loads(_RESULTS_PATH.read_text())
POST /eval/dataset uses FastAPI's BackgroundTasks and returns HTTP 202 immediately because dataset building can take several minutes. POST /eval/run is synchronous intentionally - it's typically called from a CI script that waits for the result anyway. If you need it async, move it to a background task and poll /eval/results.
🔬Interpreting Scores + CI Integration
What low scores tell you
| Metric | Low score means | Fix |
|---|---|---|
| Faithfulness < 0.5 | The LLM is making claims not in the retrieved documents - hallucinating from training data | Add a stronger system prompt: "Answer ONLY from the provided context. Never add information not present in the context." Consider a larger generation model. |
| Answer Relevancy < 0.5 | Answers are verbose, off-topic, or repeating the question without answering it | Tighten the system prompt: "Be concise and directly address the question." Check the generation model - small models sometimes repeat context verbatim instead of synthesizing. |
| Context Precision < 0.5 | The top-ranked retrieved chunks aren't the most relevant ones - noise is crowding out signal | Reduce top_k. Try a larger or better embedding model. Experiment with chunk size - smaller chunks (256 tokens) often improve precision at the cost of recall. |
| Context Recall < 0.5 | The retriever is missing chunks that contain the answer - the right content isn't being found | Increase top_k. Try adding chunk overlap during indexing. Consider a better embedding model. Check whether multi-hop questions need multiple retrieval passes. |
The precision-recall trade-off
Context Precision and Context Recall pull in opposite directions. Increasing top_k from 4 to 8 usually improves recall (more relevant chunks are included) but hurts precision (more irrelevant chunks are also included). The right balance depends on your use case:
Precision-first workloads
- Short, factual Q&A where the answer lives in one chunk
- Low
top_k(2-4), smaller chunks (256 tokens) - Prioritize: faithfulness and precision
Recall-first workloads
- Summarization, analysis, questions requiring multiple sources
- Higher
top_k(6-10), larger chunks (512-1024 tokens) - Prioritize: recall and answer relevancy
Adding evaluation to CI
The run_eval.py script exits with code 1 if any metric falls below the threshold, making it straightforward to fail a CI pipeline:
name: RAG Evaluation on: push: branches: [main] jobs: evaluate: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Start Ollama run: | curl -fsSL https://ollama.ai/install.sh | sh ollama serve & ollama pull mistral:7b ollama pull nomic-embed-text ollama pull llama3.2:3b - name: Install deps run: pip install -r requirements.txt - name: Start services run: docker compose up -d chromadb && sleep 5 - name: Load test documents run: python scripts/seed_eval_documents.py - name: Run RAGAS evaluation run: python run_eval.py --samples 20 --fail-below 0.7
Iterating on your pipeline
The right workflow is: change one variable, run eval, compare scores. Keep eval_dataset.json stable across iterations (regenerate only when the document corpus changes) so you're measuring the same questions each time. What to tune, in order of impact:
From guessing to measuring
You now have a reproducible eval loop: build a synthetic dataset from your documents, run four RAGAS metrics with local Ollama models, and fail your CI pipeline when quality drops. No paid APIs, no subscriptions, no human labelers.
The next article goes one step further: building a knowledge graph on top of your documents to enable multi-hop reasoning - answering questions that require connecting information across multiple source chunks that share no embedding similarity.
Article 6 → GraphRAG: Multi-Hop Reasoning with a Local Knowledge Graph →