Agentic AI in DevOps: From Concept to Practice
Agentic AI brings autonomous, decision-making capabilities into DevOps workflows. By embedding adaptive agents into pipelines and operations, teams can improve efficiency and resilience-provided governance, observability, and control boundaries are carefully designed.


Embracing Agentic AI in DevOps: The Definitive Senior Practitioner's Guide
From demo to production at scale - a deep technical guide covering multi-agent orchestration, MCP architecture and security, agentic CI/CD with real code patterns, self-healing SRE, FinOps intelligence, AI governance (OWASP ASI 2026), a 90-day adoption roadmap, and the emerging role of the "Human-on-the-Loop" engineer in 2026.
📊1. Market Landscape & 2026 State of Play
The narrative of 2025 was potential. The narrative of 2026 is proof. Organizations that treated agentic AI as a proof-of-concept exercise are now being forced into a binary decision: industrialise or fall behind. The market numbers reflect this inflection with unusual clarity.
Gartner warns that over 40% of agentic AI projects will be cancelled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. The projects that survive will be differentiated by architectural discipline, not model quality.
The DevOps and SRE domains are uniquely well-positioned for agentic adoption. They have three properties that make agents work in practice: well-defined operational patterns, abundant structured telemetry data, and clear, measurable success criteria (MTTR, deployment frequency, error budget burn rate). This is not accidental. It is the result of a decade of SRE discipline creating precisely the kind of machine-readable environment agents require.
Vertical Breakdown: Where Agentic AI Is Landing First
Adoption is not uniform across industries. The sectors with the highest agent density share a common profile: regulated environments with high operational complexity, abundant structured data, and significant costs attached to human toil. Financial services leads because the ROI of automating compliance monitoring and incident response is quantifiable. Hyperscale cloud-native companies follow because they were already operating at a scale that made human-in-the-loop for every alert economically unviable.
| Vertical | Primary Agent Use Case | Adoption Stage (2026) | Key Constraint | Typical ROI Driver |
|---|---|---|---|---|
| Financial Services | Compliance monitoring, incident response | Production at scale | Regulatory audit trail requirements | MTTR, compliance cost reduction |
| E-commerce / Retail | Predictive scaling, FinOps, fraud detection | Supervised production | Peak traffic unpredictability | Cloud waste, availability SLAs |
| SaaS / Cloud-Native | CI/CD automation, self-healing pipelines | Production at scale | Multi-tenant blast-radius isolation | Deployment frequency, toil elimination |
| Healthcare / Pharma | Infrastructure compliance, patch management | Supervised pilots | HIPAA / FDA validation requirements | Audit readiness, patch SLA compliance |
| Telecoms | Network anomaly detection, capacity planning | Early production | Legacy OSS/BSS integration complexity | Network uptime, capacity efficiency |
| Manufacturing / OT | Predictive maintenance, edge agent orchestration | Piloting | OT/IT convergence and safety certification | Downtime prevention, maintenance cost |
🏗2. The Architectural Shift: From Automation to Autonomy
The distinction between classic DevOps automation and agentic AI is not a matter of degree - it is a categorical architectural change. Understanding this difference is essential before any implementation decision.
- →Follows predetermined scripts and runbooks
- →Requires human intervention at decision forks
- →Request-response pattern: one input, one output
- →State is ephemeral or externally managed
- →Fails silently or pages humans at 3 AM
- →Only as smart as the last runbook update
- ✓Receives goals and works toward them autonomously
- ✓Calls APIs, queries databases, executes code in loops
- ✓Evaluates results and corrects its own approach
- ✓Maintains context and memory across sessions
- ✓Escalates with confidence scores and impact analysis
- ✓Learns from incident patterns without retraining
"Agentic AI acts as a first-pass executor across the software development lifecycle - analysing feasibility during planning, implementing features during build, expanding test coverage during validation, and surfacing risks during review." - CIO.com, 2026
The Four Autonomy Tiers
Not all "agentic" systems are equivalent. Senior engineers should be deliberate about which tier they are building toward, since each tier demands different governance models and carries different blast-radius risks.
IBM describes the emerging paradigm as "Objective-Validation Protocol": engineers define goals and validate progress, while collections of agents autonomously execute and request human approval at critical checkpoints. This is a fundamental shift from writing scripts to writing policies.
The ReAct Pattern: How Agents Actually Reason
Understanding ReAct (Reason + Act) - the dominant reasoning pattern powering production agents - is essential for every senior engineer working in this space. A ReAct agent interleaves reasoning steps ("Thought") with tool invocations ("Action") and observation of results ("Observation") in a loop until a terminal condition is met. This is not prompt magic: it is a structured inference loop where the LLM generates structured JSON tool calls, the framework executes them, and injects results back into the context window for the next reasoning step.
# Iteration 1 Thought: The alert indicates high CPU on pod api-gateway-7d9f. I need to check recent deployments and current resource limits before acting. Action: kubectl_get_events(namespace="production", pod="api-gateway-7d9f") Obs: Last deployment 14 min ago. OOMKilled × 3 in past 10 min. # Iteration 2 Thought: OOMKilled post-deploy → likely a memory regression in the new image. Check resource limits and compare with previous deployment spec. Action: kubectl_describe_deployment(name="api-gateway") Obs: limits.memory: 256Mi (was 512Mi in previous revision). Diff confirmed. # Iteration 3 Thought: Root cause identified: memory limit halved in deploy config. Blast-radius score: LOW (single deployment, no stateful impact). Auto-proceed. Action: kubectl_patch_deployment(name="api-gateway", memory_limit="512Mi") Obs: Rollout complete. Pod stabilised. CPU returned to baseline. # Terminal Thought: SLO recovery confirmed. Generating post-incident PR with root cause. Action: github_create_pr(title="fix: restore api-gateway memory limit 256Mi→512Mi")
The critical insight here is that the agent's blast-radius evaluation in iteration 3 is not a hardcoded rule - it is a trained judgment encoded in the system prompt and validated against a governance policy layer. The governance layer holds the hard constraints (e.g., "never auto-proceed on stateful workloads or auth-class signals"). The LLM handles soft reasoning within that envelope.
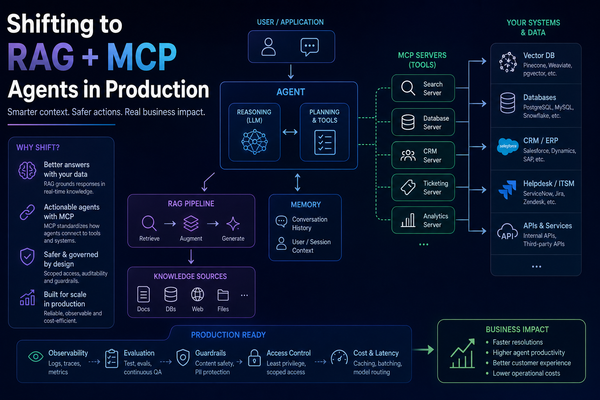
🔌3. Model Context Protocol (MCP): The Universal Backbone
No single technology has done more to accelerate production-grade agentic DevOps than the Model Context Protocol. Launched by Anthropic in November 2024, MCP achieved something rare: industry-wide adoption by competing giants including OpenAI, Google, Microsoft, and AWS within twelve months. In December 2025 it was donated to the Agentic AI Foundation under the Linux Foundation, ensuring vendor-neutral governance alongside Kubernetes and PyTorch.
MCP Evolution Timeline
2024
2025
2025
2025
2026
mcp-scan security tool released and widely adopted.2026
- →Before MCP: 10 apps × 100 tools = 1,000 custom integrations
- →After MCP: any agent connects to any tool via one standard protocol
- →Eliminates credential exposure through structured permission scoping
- →Enables multi-agent collaboration across heterogeneous systems
- ✓97M+ monthly SDK downloads (Python + TypeScript)
- ✓10,000+ active public MCP servers in official registry
- ✓Sub-50ms response times at 10,000+ concurrent connections
- ✓Native in ChatGPT, Cursor, Gemini, Microsoft Copilot
MCP in the DevOps Stack
For DevOps engineers, MCP is most transformative in the context of multi-agent pipelines. Rather than building bespoke API bridges to GitHub, Kubernetes, Datadog, PagerDuty, and your CMDB, each of those tools now exposes an MCP server. Your orchestration agent speaks a single language to all of them.
A fintech company deploying this exact pattern reduced Mean Time to Resolution from 45 minutes to under 5 minutes by deploying MCP-coordinated agents that automatically correlate alerts, identify root causes, and execute remediation playbooks - while keeping humans in the loop for production changes.
MCP Architecture: Anatomy of a Production Server
An MCP server is a lightweight process that exposes three primitives to any connected agent client: Tools (callable functions with typed input/output schemas), Resources (read-only data contexts like logs, configs, or documentation), and Prompts (reusable prompt templates parameterized for specific workflows). Understanding this separation matters for security: a resource cannot execute code; only tools can trigger side effects - and tools are where permission scoping and audit logging must be applied.
As Thoughtworks put it in their 2025 Technology Radar: "the S in MCP stands for security." The four primary attack vectors to guard against are: tool poisoning (malicious MCP tool descriptions that redirect agent behaviour), silent tool mutation (server-side definition changes between calls), cross-server tool shadowing (malicious agent intercepting calls to a trusted server), and prompt injection via tool responses. Implement toxic flow analysis and deploy mcp-scan against all servers before production rollout.
🤖4. Multi-Agent Orchestration Frameworks in Depth
Six frameworks now dominate the enterprise agentic AI landscape. Selecting the wrong one is the leading cause of scaling failures and abandoned projects. The decision hinges on your workflow topology, existing tech stack, and the balance between flexibility and production-hardening.
LangGraph
From the LangChain ecosystem. Instead of linear chains, you define a state machine with nodes, edges, and conditional routing. Supports parallel execution, persistent state, and human-in-the-loop checkpoints natively. Trusted in production by Klarna, Replit, and Elastic. Best fit for complex stateful workflows with conditional logic and compliance requirements.
Microsoft AutoGen v0.4
Complete architecture redesign released January 2025. Adopts an asynchronous event-driven architecture across three layers: Core (foundational primitives), AgentChat (high-level task orchestration), and Extensions (Azure integrations). Purpose-built for enterprise reliability, Azure integration, and regulated environments. Best fit for Microsoft-stack shops.
CrewAI
Pioneered role-based agent design: you define "crew members" with explicit roles, goals, and backstories. Dramatically reduces time to a working prototype. Strong for hierarchical task decomposition. Best fit for rapid prototyping and role-based collaboration where agents mirror human team structures.
Semantic Kernel
Deep integration with .NET ecosystem, Python, and JavaScript. Designed for enterprise applications where AI needs to reason and act across multiple services. Plugin architecture enables incremental AI adoption in existing codebases. Best fit for .NET-heavy enterprises adding intelligence to existing applications.
AWS Bedrock Agents
Fully managed orchestration on AWS infrastructure. Native integration with Bedrock models, Lambda, S3, and Aurora. Knowledge bases with built-in RAG. Simplest path to production for AWS-native teams. Best fit for organizations wanting managed infrastructure and avoiding DIY orchestration complexity.
Vertex AI Agents
Google's answer to Bedrock. Tight integration with Gemini models, BigQuery, and Vertex AI Search. Agent Builder enables low-code composition for teams that don't need full programmatic control. Best fit for GCP-native organizations and teams working with structured data at scale.
Framework Selection Decision Matrix
| Framework | Workflow Complexity | State Management | Enterprise Auth | MCP Native | Learning Curve | Best For |
|---|---|---|---|---|---|---|
| LangGraph | Very High | Native (graph state) | Custom | Via LangChain | High | Complex conditional flows |
| AutoGen v0.4 | High | Event-driven async | Azure AD native | Extensions layer | High | Azure enterprise, .NET |
| CrewAI | Medium | Task-scoped | Custom | Via adapters | Low | Rapid prototyping |
| Semantic Kernel | Medium-High | Plugin-based | Entra / Azure AD | Plugin adapters | Medium | .NET ecosystems |
| Bedrock Agents | Medium | Session-managed | IAM / Cognito | AgentCore Runtime | Low | AWS-native teams |
| Vertex AI Agents | Medium | Session-managed | IAM / Workload Identity | Via extensions | Low | GCP-native teams |
When to Build vs. When to Buy
The "build vs. buy" question has a cleaner answer in 2026 than it did in 2024. The decision hinges on two axes: workflow uniqueness (how different your agent topology is from what the platform provides out of the box) and operational ownership tolerance (whether your team can maintain a custom orchestration runtime). Cloud-managed options (Bedrock, Vertex) have closed the flexibility gap significantly, but they introduce vendor lock-in that becomes painful at the framework-migration layer.
LangGraph is a graph execution engine - you define nodes, edges, and state transitions. It gives you full control but requires you to understand graph theory and debug execution traces. CrewAI is a role orchestration framework - you define agents by persona and goal, and it handles the task decomposition. Use LangGraph when your workflow has complex conditional branching, human-in-the-loop checkpoints, or compliance audit requirements. Use CrewAI when you need a working multi-agent prototype in a day and the workflow is relatively linear. Mixing them in the same codebase is a red flag.
⚙️5. Agentic CI/CD: Autonomous Pipelines
The integration of AI agents into CI/CD pipelines is the most immediate value-creation opportunity for most DevOps teams. The shift is from pipelines that execute steps humans designed to pipelines that reason about what steps should run and why.
What Agentic CI/CD Actually Looks Like
Tools like GitHub Copilot Agent Mode and Harness AI now go well beyond code suggestions. They generate entire IaC configurations, predict pipeline failures, and execute safe rollbacks autonomously. CircleCI's MCP server, available via AWS Marketplace, enables AI development tools to execute CI/CD operations through natural language interactions - including build debugging, test analysis, configuration management, and deployment controls - maintaining enterprise security through OAuth-based authentication.
PR Risk Scoring
Agents evaluate pull requests by comparing against thousands of previous successful and failed deployments, assigning a deployment risk score before a single line reaches production. Teams report 30-50% reductions in broken deployments.
Intelligent Test Orchestration
Agents analyse code change diffs and selectively run only the affected test suites, with dynamic timeout adjustments based on historical run data. Playwright and Selenium now expose MCP servers enabling agentic UI test authoring.
Continuous Security Scanning
Agents continuously scan dependencies for CVEs. When a high-severity patch is released for a container image, the agent automatically opens a PR with the updated version, pre-verified against internal security policy. Snyk 4.1 introduced enhanced container image scanning with risk-impact prioritization in 2026.
IaC Generation & Drift Detection
Agents anchor to reference application templates via MCP servers, detect configuration drift between the live state and IaC definitions, and raise fix PRs with supporting context. GitOps early adopters reported 50% reductions in configuration drift.
Autonomous Rollback
Deployment agents monitor error budgets and SLO burn rates post-deploy. On detecting anomalous burn, they trigger automated rollbacks against pre-approved canary thresholds without requiring a human page.
Post-Incident Documentation
After resolution, agents automatically generate structured post-incident reports, update runbook pages, and tag affected components in the CMDB - eliminating the most hated SRE toil.
Implementing PR Risk Scoring: A Concrete Pattern
PR risk scoring is the highest-ROI entry point for agentic CI/CD because it is Tier 1-2 (assistive to supervised), low blast-radius, and immediately measurable. The pattern below shows a LangGraph-based implementation that evaluates every incoming PR against four risk axes and posts a structured review comment before any human reviews the code.
from langgraph.graph import StateGraph, END from langchain_anthropic import ChatAnthropic from typing import TypedDict, Annotated import operator class PRState(TypedDict): pr_diff: str changed_files: list[str] test_coverage_delta: float risk_axes: Annotated[list, operator.add] # accumulates across nodes final_score: float recommendation: str llm = ChatAnthropic(model="claude-opus-4-6", max_tokens=2048) def analyse_blast_radius(state: PRState) -> dict: # Checks: do changed files touch auth, payments, or DB migrations? high_risk_patterns = ["auth/", "migrations/", "payment/", "security/"] hits = [f for f in state["changed_files"] if any(p in f for p in high_risk_patterns)] score = 0.9 if hits else 0.2 return {"risk_axes": [{"axis": "blast_radius", "score": score, "detail": f"Sensitive paths touched: {hits}"}]} def analyse_test_coverage(state: PRState) -> dict: delta = state["test_coverage_delta"] # negative = coverage dropped score = max(0.0, min(1.0, (-delta + 5) / 20)) # normalise to 0-1 return {"risk_axes": [{"axis": "test_coverage", "score": score, "detail": f"Coverage delta: {delta:+.1f}%"}]} def llm_semantic_review(state: PRState) -> dict: # LLM reviews the diff for logical issues, security anti-patterns response = llm.invoke([{ "role": "user", "content": f"Review this diff for security issues and logic errors. Score risk 0.0-1.0 and explain.\n\n{state['pr_diff'][:4000]}" }]) # parse structured output from response... return {"risk_axes": [{"axis": "semantic", "score": 0.4, "detail": response.content}]} def compute_final_score(state: PRState) -> dict: weights = {"blast_radius": 0.4, "test_coverage": 0.3, "semantic": 0.3} score = sum(ax["score"] * weights.get(ax["axis"], 0.1) for ax in state["risk_axes"]) rec = "BLOCK" if score > 0.7 else "REVIEW" if score > 0.4 else "APPROVE" return {"final_score": score, "recommendation": rec} # Wire graph graph = StateGraph(PRState) graph.add_node("blast_radius", analyse_blast_radius) graph.add_node("test_coverage", analyse_test_coverage) graph.add_node("semantic_review", llm_semantic_review) graph.add_node("score", compute_final_score) graph.set_entry_point("blast_radius") graph.add_edge("blast_radius", "test_coverage") graph.add_edge("test_coverage", "semantic_review") graph.add_edge("semantic_review", "score") graph.add_edge("score", END) pr_agent = graph.compile()
Autonomous CI/CD Architecture (Tier 3 Example)
🏥6. Agentic SRE & Self-Healing Infrastructure
Site Reliability Engineering is where agentic AI delivers its most dramatic and measurable outcomes. The challenge of managing thousands of microservices across multiple clouds - each generating terabytes of telemetry daily - has overwhelmed traditional runbook-based SRE. Alert fatigue, context-switching between dozens of monitoring tools, and MTTR creeping upward despite massive observability investments: these are the problems Agentic SRE is built to solve.
"Agentic SRE operates through coordinated multi-agent structures. One agent detects anomalies. Another evaluates probable root causes. A third executes remediation actions. A fourth verifies recovery." - Unite.AI, 2026
The Closed-Loop Reliability Pipeline
Modern Agentic SRE systems rely on three core data layers: a unified data plane (OpenTelemetry-standardised logs, metrics, traces, and events), a reasoning layer (LLM-powered root cause analysis with pattern caching for known incidents), and an action layer (guardrailed execution with blast-radius scoring and human escalation gates).
Fintech MTTR: Reduced from 45 minutes to under 5 minutes via MCP-coordinated incident response agents. E-commerce capacity planning: Prediction agents scale infrastructure hours before demand spikes, maintaining performance while reducing cloud waste. SaaS security posture: Continuous CVE scanning agents auto-apply low-risk patches during maintenance windows. Kubernetes SRE (Metoro v2.8): A financial services firm reported 60% MTTR reduction. An e-commerce company reported 40% incident resolution time reduction.
The Alert Fatigue Crisis - and Why Agents Fix It Structurally
Traditional observability generates noise by design: static thresholds emit alerts the moment a metric crosses a line, with no understanding of business context, time-of-day patterns, or correlated causality. The result: SRE teams at median-sized companies receive 200-400 alerts per day, of which industry surveys consistently show 40-60% are false positives or low-actionability signals. Engineers develop alert fatigue, critical signals get missed, and MTTR climbs as teams become desensitised to pages.
Agentic SRE attacks this structurally rather than symptomatically. Instead of tuning thresholds (the standard remediation), agents replace threshold-based alerting with anomaly-based detection over full telemetry context. Dynatrace Davis AI, for example, evaluates every metric against its own historical baseline, seasonality patterns, and correlated signals across the dependency graph. The result is a 60-80% reduction in false positives - not by suppressing alerts, but by understanding what "normal" means for each specific signal in context.
Kubernetes-Native Agentic SRE in Practice
In 2026, SRE agents manage Kubernetes clusters with predictive precision. When a pod crashes, an agent cordons the node, analyses the heap dump, and scales the Horizontal Pod Autoscaler based on predicted traffic bursts rather than static thresholds. The key tools in the stack are Dynatrace (Davis AI engine), PagerDuty AIOps, Metoro (eBPF-based telemetry for autonomous anomaly detection), Cast AI (predictive autoscaling), New Relic, and Datadog - all evolving toward agentic incident response in 2026.
| Agentic SRE Capability | Tool / Platform | Mechanism | Typical Outcome | Autonomy Tier |
|---|---|---|---|---|
| Anomaly Detection | Dynatrace Davis AI, Datadog | ML on OTLP telemetry streams | False positive reduction 60-80% | Tier 1 |
| Root Cause Analysis | Metoro, New Relic AI | eBPF telemetry + LLM reasoning loop | RCA in <2 minutes vs 30+ manual | Tier 2 |
| Auto-Remediation | PagerDuty AIOps, custom LangGraph | Runbook agent with blast-radius gate | 40-60% MTTR reduction | Tier 3 |
| Predictive Scaling | Cast AI, KEDA + Agents | Traffic pattern prediction + HPA override | Cost reduction 25-40% | Tier 3 |
| Patch Automation | Snyk 4.1 + Agents | CVE scan → risk score → auto-PR | Patch lag reduced from weeks to hours | Tier 4 |
| Self-Healing Pipelines | LangGraph + Claude 3.5 Sonnet | ReAct loop with incident pattern cache | Up to 90% of incidents auto-resolved | Tier 4 |
🛡7. Security, Governance & OWASP Agentic Top 10
The production gap - 79% experimenting, 11% in production - is almost entirely a governance problem. The technology works in controlled environments. The path to production requires observability, access control, and clear escalation paths that go well beyond current framework defaults.
Microsoft released the Agent Governance Toolkit in April 2026 as an open-source project, applying proven security concepts from operating systems, service meshes, and SRE to autonomous AI agents. Its framing is clarifying: "Most AI agent frameworks today are like running every process as root - no access controls, no isolation, no audit trail."
The OWASP Agentic Security Initiative (ASI 2026) - Top 10
The OWASP Agentic Security Initiative has published the ASI 2026 taxonomy (ASI01-ASI10), which is now the industry standard for AI agent workload security assessments, equivalent to the classic OWASP Top 10 for web applications.
| ID | Vulnerability | Description | DevOps-Specific Risk | Primary Mitigation |
|---|---|---|---|---|
| ASI01 | Prompt Injection | Malicious input overrides agent instructions | Agent executes unauthorised kubectl commands | Input sanitisation, sandboxed execution |
| ASI02 | Excessive Privilege | Agent holds broader permissions than needed for its task | Remediation agent can read customer PII | Principle of least privilege per agent role |
| ASI03 | Tool Poisoning | MCP tool contains a malicious or misleading description | Agent routes traffic to attacker-controlled endpoints | MCP server signature verification, mcp-scan |
| ASI04 | Insecure Tool Chaining | Agent-to-agent trust propagates without re-validation | Compromised sub-agent escalates privileges | Trust ring model, per-hop re-authorisation |
| ASI05 | Data Leakage via Context | Sensitive data in agent context window leaks to logs or sub-agents | Secrets in telemetry data exposed to reasoning LLM | Context scrubbing, secret detection pre-LLM |
| ASI06 | Uncontrolled Recursion | Agent spawns sub-agents without bound | Cost explosion, runaway infrastructure changes | Max-depth limits, cost circuit breakers |
| ASI07 | Audit Trail Gaps | Agent actions not durably logged with full context | Cannot reconstruct why a rollback was triggered | OpenTelemetry-compatible agent action tracing |
| ASI08 | Cross-Server Shadowing | Malicious MCP server intercepts calls to a trusted server | Attacker injects false diagnostic data | Server identity verification (SEP-2026 spec) |
| ASI09 | Stale Policy Execution | Agent operates on outdated governance policies | Agent approves action that violates new compliance rule | Policy versioning with automatic agent re-binding |
| ASI10 | Insufficient Human Escalation | Agent resolves ambiguous situations without escalation | Auth failure silently "fixed" by disabling checks | Hard governance gates for security-class signals |
The Five Governance Pillars
🔐 Least Privilege by Agent Role
Each agent receives only the MCP permissions necessary for its specific role. The remediation agent cannot access customer data. The observability agent cannot modify infrastructure. Define and audit permission sets at deployment time, not runtime.
👤 Human-in-the-Loop Gates
Critical operations require human approval with confidence scores and impact analysis presented before execution. Hard governance decisions (auth failures, production data modifications) should always escalate regardless of confidence level.
📊 Full Observability of Agent Actions
Export governance metrics via OpenTelemetry to your existing observability stack. Key metrics: policy decisions per second, trust score distributions, circuit breaker state, SLO burn rates, and governance workflow latency.
🔁 Circuit Breakers for Agent Cascades
Implement circuit breakers that halt agent action chains when anomalous behaviour is detected (unexpected cost spikes, repeated failed remediations, unusual API call patterns). Never allow unbounded agent recursion in production.
📜 Immutable Audit Trails
Every agent action must produce a durable, tamper-evident audit log with full context: what goal was given, what reasoning was applied, what action was taken, and what the outcome was. This is non-negotiable for regulated industries.
💰8. FinOps Agents & Cloud Cost Intelligence
Cloud waste is one of the highest-ROI targets for agentic AI. FinOps agents continuously monitor AWS, Azure, and GCP spend across all accounts and regions, identifying orphaned volumes, underutilised instances, over-provisioned reserved capacity, and suboptimal spot instance configurations. Organizations deploying FinOps agents report savings of 25-40% on monthly cloud bills.
The Cloud Waste Anatomy
Before deploying FinOps agents, it is worth understanding where cloud waste concentrates. Flexera's 2025 State of the Cloud report found that organizations waste an average of 32% of their cloud spend. The breakdown is instructive for prioritising where to aim agents first: compute (idle and oversized instances) accounts for approximately 45% of total waste, followed by storage (orphaned volumes, misconfigured lifecycle policies) at 25%, network egress at 15%, and licensing mismatches at 15%. Agents are most effective at the compute and storage layers - these are the domains with sufficient telemetry, clear decision criteria, and bounded blast-radius for autonomous action.
- →Detect and flag orphaned EBS volumes, idle load balancers, zombie resources
- →Recommend reserved instance purchases based on 90-day usage analysis
- →Auto-migrate workloads to spot instances within approved risk tolerance
- →Right-size under-utilised EC2/GCE/AKS node groups
- →Tag untagged resources with inferred cost centre and team ownership
- ⚠Termination of running workloads (even suspected idle ones)
- ⚠Reserved instance purchases above configured spend thresholds
- ⚠Cross-account budget reallocation
- ⚠Any action affecting production databases or stateful workloads
- ⚠Contract renegotiations with cloud providers
⚠️9. Anti-Patterns & Production Pitfalls
The 40% project cancellation rate Gartner projects for 2027 will not be random. It will concentrate heavily in teams that fell into the following well-documented failure modes. Each represents a mistake that is cheap to avoid in architecture and expensive to untangle in production.
mcp-scan against all MCP servers before production use. Maintain an internal registry of approved servers with their exact versioned digests. Implement server identity verification once the MCP Streamable HTTP transport matures in mid-2026.👤10. The Human-on-the-Loop: Career & Team Transformation
The most profound change agentic AI brings to DevOps is not operational - it is professional. The role of the senior engineer is shifting from executor to architect and supervisor. Infrastructure that was managed and monitored manually is increasingly delegated to agents. But humans do not disappear from the loop - they move to a fundamentally more strategic position within it.
"Human-on-the-Loop replaces direct operational execution with oversight and governance. Engineers define policies, specify acceptable actions, encode business intent. They evaluate outcomes rather than perform repetitive interventions." - Unite.AI, 2026
Emerging Roles in the AgenticOps Era
AI Infrastructure Engineer
Owns the agent runtime infrastructure: LLM API gateway management, agent observability stack, MCP server registry, cost circuit breakers, and the physical compute fabric (GPU clusters, edge AI nodes). Bridges classical SRE with AI systems reliability.
Agent Reliability Engineer
An emerging specialisation that treats agent systems as production workloads requiring SLOs, error budgets, and runbooks. Responsible for agent behaviour under adversarial conditions, prompt injection defenses, sandbox execution environments, and governance framework maintenance.
AI Workflow Architect
Designs multi-agent topologies: what agents exist, what their trust relationships are, what MCP tools they have access to, and where human checkpoints are mandatory. Translates business intent into governance policies and agent permission graphs.
Policy Engineer
The evolution of the classic "Platform Engineer." Writes the policies that constrain agent behaviour: escalation rules, blast-radius limits, cost budgets, compliance guardrails. In the Objective-Validation Protocol era, this is the highest-leverage engineering role.
The 90-Day Adoption Roadmap: From Zero to Supervised Production
The most common failure mode for teams entering agentic AI is trying to boil the ocean. The following roadmap is a disciplined, phased approach validated across multiple production rollouts. Each phase has a clear exit criterion. You do not proceed to the next phase until the current one is met.
D14
D30
D60
D75
D90
Skills the 2026 Senior AIxDevOps Engineer Needs
By 2028, Splunk estimates approximately 1.3 billion active agents operating across corporate networks. Google Cloud projects agentic AI contributing to a $1 trillion market realisation by 2040. The organisations that will capture that value are the ones building governance-first agentic architectures today - before the regulatory frameworks arrive and force reactive compliance.
From Automation to Autonomy - The Time Is Now
Agentic AI in DevOps is not a future capability. It is a present competitive differentiation. The technology stack - MCP, mature orchestration frameworks, production-grade observability, and the OWASP ASI governance standard - is fully available. What separates the 11% running agents in production from the 61% stuck in exploration is disciplined engineering: the right framework for the right workflow, governance-first architecture, and a team that understands the shift from writing scripts to writing policies.
The senior engineers who invest today in agent reliability, MCP security, and multi-agent architecture will be the architects of the autonomous enterprise. Those who wait for the technology to mature will find the governance gap closed by regulation rather than by design.