The Hidden Failure Mode of RAG Systems: Right Data, Wrong Answer
Your RAG retrieves the right documents - then hallucinates anyway. The culprit isn't the model or the retriever. It's conflicting context entering the generator undetected. Here's the architectural fix five research groups converged on in 2025–2026.

The Hidden Failure Mode of RAG Systems: Right Data, Wrong Answer
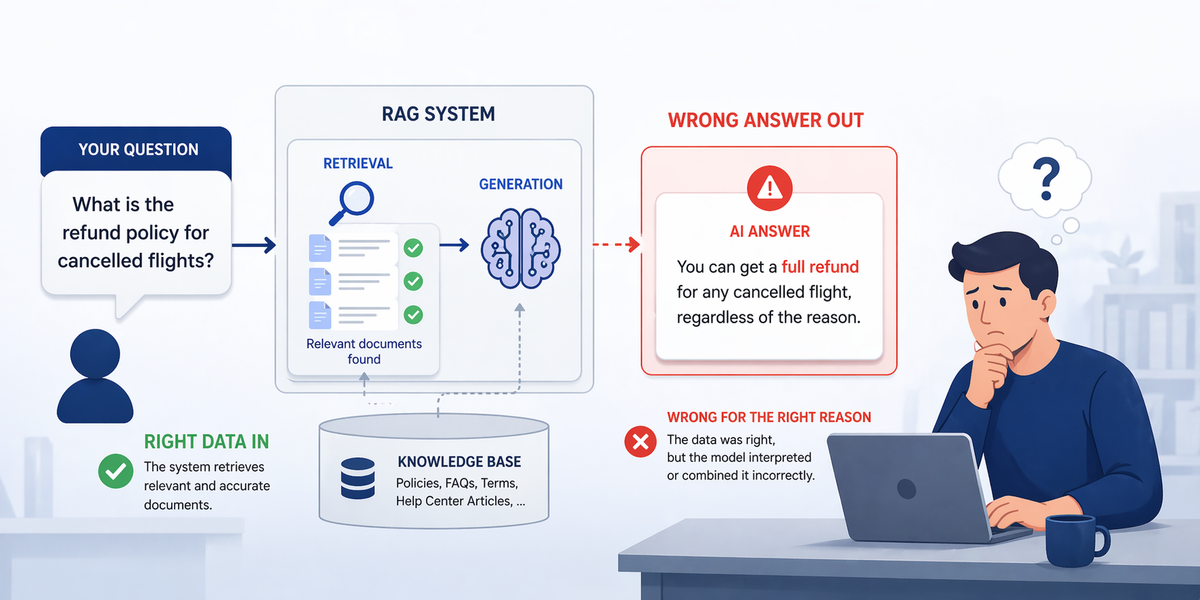
Your RAG system retrieves the right documents with perfect cosine scores - yet still confidently returns the wrong answer. This is not a model deficiency. It is an architectural gap that almost every production RAG pipeline ignores: conflicting context entering the generator without any detection or resolution stage.
⚡ 01 - Introduction: The Invisible Problem
There is a moment every AI engineer who has shipped a production RAG system knows well. The retrieval scores look perfect. The documents are exactly right. You watch the context get assembled and passed to the LLM - and then the model confidently states something incorrect. Something that directly contradicts one of the retrieved documents.
You are not dealing with a retrieval problem. You are not dealing with a model problem. You are dealing with a context conflict problem - and your pipeline has no mechanism to detect or resolve it.
Research published at ICLR 2025 by Joren et al. demonstrates that frontier models including Gemini 1.5 Pro, GPT-4o, and Claude 3.5 frequently produce incorrect answers rather than abstaining when retrieved context is insufficient or contradictory - and that this failure is not reflected in the model's expressed confidence. The model will sound equally certain whether it is right or wrong. This is the hidden failure mode.
Poorly evaluated RAG systems can produce hallucinations in up to 40% of responses even when the correct source document was retrieved (Stanford AI Lab). The failure is not that the wrong document was retrieved. The failure is that conflicting documents were retrieved together, and the pipeline handed that contradiction to the generator without any resolution stage. The model made a choice - and it chose wrong.
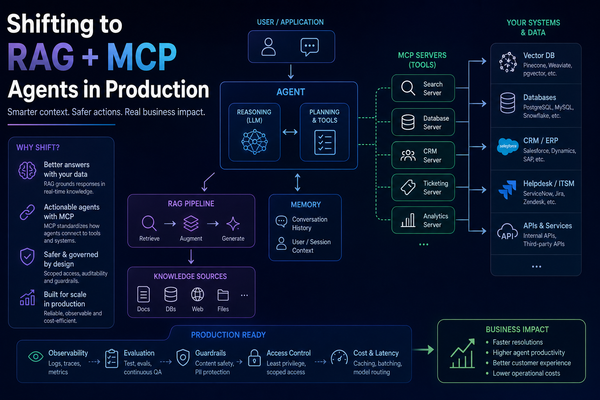
🏗️ 02 - RAG Architecture: Two Pipelines, Five Failure Points
RAG is not a single model or endpoint - it is two distinct pipelines sharing a vector store as their meeting point. Understanding this two-pipeline structure is prerequisite to understanding where failures occur and why conflicting context is structurally guaranteed in naive implementations.
The Five Silent Failure Points
Every arrow in the pipeline above is a potential failure point. Teams that only optimise the last step - the LLM - will keep encountering failures they cannot diagnose because they have no telemetry on the four upstream stages.
| Failure Point | Stage | Failure Mechanism | Symptom | Severity |
|---|---|---|---|---|
| Missing Document | Indexing | Answer not in knowledge base at all | Model says "I don't know" or hallucinates from training memory | Medium |
| Missed Ranking | Retrieval | Correct document exists but is not in the top-k result set | Fluent answer citing wrong or less relevant document | Medium |
| Context Overflow | Assembly | Too many retrieved chunks dilute attention and add conflicting noise | Generic, hedged answers; inconsistent facts across response | High |
| Context Conflict | Assembly | Two or more retrieved chunks contain contradictory information | Confident wrong answer or answer blending both contradictory facts | Critical |
| Format Mismatch | Generation | LLM ignores format requirements or produces unstructured output for structured queries | Correct facts in wrong format, user cannot consume output | Medium |
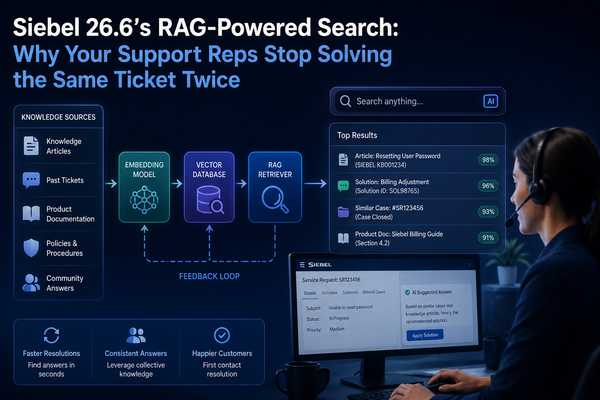
🔧 03 - Core Technologies and the Retrieval Stack
Before addressing the failure mode, we need to establish what a production retrieval stack looks like in 2026. The naive "embed and retrieve" approach of 2022 has been replaced by a hybrid multi-stage pipeline. Understanding each component explains why even a well-built retrieval pipeline is insufficient to prevent context conflicts.
The 2026 Production Retrieval Stack
Key Tools and Frameworks in the Current Stack
🔴 04 - The Hidden Failure Mode: Conflicting Context
Here is the exact failure mode, stated precisely: a production RAG system retrieves multiple documents that all have high relevance scores. The retrieval step succeeded. But two or more of those documents contain contradictory information about the same fact. The context assembler concatenates them all and passes the contradiction to the LLM. The LLM does not abstain. It makes a choice between the conflicting versions - and that choice is not visible in any retrieval metric.
"The failure is not a model deficiency. It is an architectural gap: the pipeline has no stage that detects contradictions before handing context to generation. A modular conflict detector must sit between retrieval and generation." - Towards Data Science, April 2026
Why This Failure Is Invisible
The conflict failure mode has three properties that make it particularly dangerous in production:
- xContext precision is high - both conflicting documents are genuinely relevant
- xFaithfulness may be reported as 1.0 - the answer is supported by at least one retrieved document
- xAnswer relevance is high - the answer addresses the question
- xThe model expresses high confidence - it does not distinguish between settled and contested context
- xTraditional ROUGE/BLEU scores do not penalise factual contradiction at all
- →Research (Tan et al., 2024) shows LLMs exhibit confirmation bias toward self-generated contexts when evidence is both supporting and conflicting
- →Gao et al. (2025) found: irrelevant context is often amplified when it is aligned with parametric memory
- →Knowledge integration occurs hierarchically in LLM hidden states - early layers absorb context, later layers apply parametric override
- →The "winning" answer in a conflict is often the one that matches training data most closely - not the most recent document
Probing-based analysis of LLM hidden-state representations across conflict scenarios revealed three critical findings: first, knowledge integration occurs hierarchically - different transformer layers process parametric memory and retrieved context at different stages. Second, conflicts manifest as latent signals at the sentence level, not at the document level. Third, and most concerning: irrelevant context is systematically amplified when it happens to align with what the model already believes from pre-training. This means the model will favour stale training knowledge over fresher retrieved evidence in many conflict scenarios.
🗂️ 05 - Taxonomy of Knowledge Conflicts in RAG
The CONFLICTS benchmark (Cattan et al., 2025, Google Research) introduced the first rigorous taxonomy of knowledge conflicts in realistic RAG settings. Their key finding: different conflict types require fundamentally different resolution strategies. A system that treats all conflicts identically will fail on most of them. This taxonomy is now the industry standard for conflict classification.
Temporal Staleness: Which Version Is Current?
Two documents contain different values for the same fact because the knowledge base has not been updated uniformly. One document reflects the current state; another reflects the historical state. Both were retrieved as highly relevant.
Resolution strategy: Prioritise the document with the most recent metadata timestamp. Inject document age signals into the context assembler.
Contested Knowledge: No Single Correct Answer
Multiple sources legitimately disagree because the matter is genuinely contested - different experts, different methodologies, or different use-case contexts. There is no single "correct" answer to surface.
Resolution strategy: Do not force a single answer. The model should acknowledge the disagreement and present the key perspectives. Flag to the user that the topic is contested.
Partial Truth: Each Document Has a Piece
Individual documents each contain accurate but incomplete information. No single document has the full picture. A system that retrieves only the top-1 document will produce an incomplete answer; retrieving multiple produces apparent contradiction.
Resolution strategy: Multi-hop retrieval and synthesis. The conflict detector should identify that the documents are complementary, not contradictory, and prompt the generator to synthesise rather than choose.
Active Contradiction: One Source Is Wrong
One or more retrieved documents contain factually incorrect information - from an unreliable source, from a document that was never fact-checked, or from a PoisonedRAG-style injection attack against the knowledge base.
Resolution strategy: Source credibility ranking. Assign trust scores to document sources. Flag when a low-credibility document contradicts a high-credibility document. Require explicit escalation for medical, legal, and financial conflicts.
🔍 06 - The Missing Stage: Conflict Detection Before Generation
The architectural fix is concrete and modular: insert a conflict detection stage between context assembly and generation. This stage does not replace retrieval or re-ranking - it receives their output and adds a new signal: whether the retrieved documents are consistent, and if not, what type of conflict they contain.
The TCR Framework: State of the Art (2026)
The TCR (Transparent Conflict Resolution) framework from Ye et al. (2026) is the current state-of-the-art published solution. Its design is instructive because it shows exactly what the conflict detection stage needs to do:
| TCR Component | What It Does | Why It Matters | Performance Gain |
|---|---|---|---|
| Dual Contrastive Encoders | Disentangles semantic relevance from factual consistency as separate signals | Standard retrieval conflates the two - high similarity does not mean consistent facts | +5-18 F1 on conflict detection across 7 benchmarks |
| Self-Answerability Estimation | Gauges the LLM's confidence in its parametric memory for the query | Determines whether to trust retrieved context or parametric knowledge more heavily | +21.4pp knowledge-gap recovery |
| Soft-Prompt Injection | Injects conflict signals as lightweight soft prompts into the generator | Only 0.3% additional parameters - negligible overhead vs. repeated LLM calls | −29.3pp misleading-context overrides |
A Practical Conflict Detector - Python Implementation
from __future__ import annotations from typing import Literal from pydantic import BaseModel, Field from langchain_anthropic import ChatAnthropic from langchain_core.messages import HumanMessage, SystemMessage from langchain_core.prompts import ChatPromptTemplate # ── Structured output schema for conflict classification ── class ConflictAnalysis(BaseModel): conflict_detected: bool = Field( description="True if any two retrieved chunks contain contradictory information" ) conflict_type: Literal[ "none", "freshness", "opinion", "complementary", "misinformation" ] = Field(description="Type of conflict following the CONFLICTS benchmark taxonomy") conflicting_indices: list[int] = Field( description="Zero-based indices of chunks that conflict with each other", default_factory=list ) resolution_strategy: Literal[ "trust_most_recent", "present_perspectives", "synthesise_complementary", "flag_and_escalate", "proceed_normally" ] = Field(description="How the generator should handle this conflict type") confidence: float = Field(ge=0.0, le=1.0, description="Confidence in the conflict classification") # ── Use a cheap, fast model for conflict detection ── # claude-haiku-4-5-20251001: fastest Claude model - ideal for the detection # stage. Never use the same model for detection AND generation: correlated # errors defeat the purpose of the independent validator. detector_llm = ChatAnthropic( model="claude-haiku-4-5-20251001", max_tokens=512, ).with_structured_output(ConflictAnalysis) # Haiku token budget for the detector: ~1,500 tokens input keeps latency # below 200ms and cost under $0.0002 per call. _DETECTOR_CHAR_LIMIT = 6_000 # ~1,500 tokens @ 4 chars/token DETECTOR_SYSTEM = """You are a knowledge conflict detector for a RAG system. Given a user query and a list of retrieved document chunks, identify: 1. Whether any chunks contain contradictory information about the SAME specific fact. 2. Which conflict type applies: freshness / opinion / complementary / misinformation / none. 3. The appropriate resolution strategy. Be conservative: different angles on the same topic are NOT conflicts. Only flag when two chunks assert opposite values for the same concrete claim.""" conflict_prompt = ChatPromptTemplate.from_messages([ ("system", DETECTOR_SYSTEM), ("human", "Query: {query}\n\nRetrieved Chunks:\n{chunks_formatted}"), ]) def detect_conflict(query: str, chunks: list[str]) -> ConflictAnalysis: chunks_formatted = "\n\n".join( f"[CHUNK {i}]:\n{chunk}" for i, chunk in enumerate(chunks) ) # Hard-truncate to keep the detector fast and cheap if len(chunks_formatted) > _DETECTOR_CHAR_LIMIT: chunks_formatted = chunks_formatted[:_DETECTOR_CHAR_LIMIT] return (conflict_prompt | detector_llm).invoke({ "query": query, "chunks_formatted": chunks_formatted, }) # ── Resolution-aware generation ── RESOLUTION_INSTRUCTIONS: dict[str, str] = { "trust_most_recent": "Sources conflict on temporal facts. Prioritise the most recently dated source and explicitly note the discrepancy to the user.", "present_perspectives": "Sources express differing expert opinions. Present the key perspectives rather than picking one; flag this as a contested topic.", "synthesise_complementary":"Sources are complementary, not contradictory. Synthesise them into a single complete answer.", "flag_and_escalate": "WARNING: Sources contain a direct factual contradiction. State the contradiction explicitly and recommend consulting authoritative primary sources. Do not choose a side.", "proceed_normally": "Sources are consistent. Answer based on retrieved context.", } def conflict_aware_generate(query: str, chunks: list[str], llm: ChatAnthropic) -> str: analysis: ConflictAnalysis = detect_conflict(query, chunks) resolution_instruction = RESOLUTION_INSTRUCTIONS[analysis.resolution_strategy] context = "\n\n---\n\n".join(chunks) # ChatAnthropic expects LangChain message objects, not raw dicts response = llm.invoke([ SystemMessage(content=( f"You are a precise assistant. Answer the question using ONLY the retrieved context.\n" f"{resolution_instruction}\n" f"If the answer is not in the retrieved context, say so explicitly." )), HumanMessage(content=f"Context:\n{context}\n\nQuestion: {query}"), ]) return response.content
📏 07 - Evaluating Context Assembly and Generation
The RAGAS framework defines the four metrics that together cover the RAG evaluation surface completely. Understanding what each metric measures - and what each metric does not measure - is essential for diagnosing which part of the pipeline is failing.
| Metric | What It Measures | What It Misses | Needs Ground Truth? | Production Target |
|---|---|---|---|---|
| Context Precision | Fraction of top-k chunks that are genuinely relevant | Whether relevant chunks agree with each other | No (LLM judge) | ≥ 0.8 |
| Context Recall | Fraction of answer-supporting facts that were retrieved | Quality or consistency of retrieved facts | Yes (ground truth) | ≥ 0.75 |
| Faithfulness | Every claim in the answer is traceable to a retrieved chunk | Whether the cited chunk is actually correct | No (LLM judge) | ≥ 0.85 |
| Answer Relevance | Answer addresses the question that was asked | Factual accuracy of the answer | No (LLM judge) | ≥ 0.80 |
| Conflict Score | Whether retrieved chunks are mutually consistent | - (this is the gap these metrics leave) | No (conflict detector) | ≥ 0.90 (no conflict) |
A RAG system can score perfectly on all four standard RAGAS metrics and still have a 40% hallucination rate on queries where retrieved documents conflict. Faithfulness = 1.0 means every claim is in at least one retrieved document. It says nothing about whether that document contradicts another retrieved document. You need a fifth metric: conflict score. This is the gap the CONFLICTS benchmark was designed to close.
The Evaluation Code: RAGAS + Conflict Score
from __future__ import annotations from datasets import Dataset from ragas import evaluate, EvaluationDataset from ragas.metrics import ( LLMContextPrecisionWithoutReference, LLMContextRecall, Faithfulness, AnswerRelevancy, ) from ragas.llms import LangchainLLMWrapper # required in RAGAS ≥ 0.2 from langchain_anthropic import ChatAnthropic # ── RAGAS ≥ 0.2 requires an explicit LLM wrapper around LangChain models ── # Use Sonnet for judge tasks - Haiku is too weak for faithfulness scoring. judge_llm = LangchainLLMWrapper(ChatAnthropic(model="claude-sonnet-4-6")) context_precision = LLMContextPrecisionWithoutReference(llm=judge_llm) context_recall = LLMContextRecall(llm=judge_llm) faithfulness = Faithfulness(llm=judge_llm) answer_relevancy = AnswerRelevancy(llm=judge_llm) def compute_conflict_score(retrieved_chunks: list[str]) -> float: # Returns 1.0 (no conflict) or 0.0 (conflict detected) per chunk set. analysis = detect_conflict("", retrieved_chunks) return 0.0 if analysis.conflict_detected else 1.0 def run_full_rag_evaluation(test_cases: list[dict]) -> dict: """ test_cases: list of dicts with keys: user_input, retrieved_contexts, response, reference Returns dict of all metrics including conflict_free_rate. """ # RAGAS 0.2+ uses EvaluationDataset, not raw HuggingFace Dataset eval_dataset = EvaluationDataset.from_list(test_cases) ragas_results = evaluate( dataset=eval_dataset, metrics=[context_precision, context_recall, faithfulness, answer_relevancy], ) # Conflict score - the fifth metric missing from every standard suite conflict_scores = [ compute_conflict_score(case["retrieved_contexts"]) for case in test_cases ] conflict_free_rate = sum(conflict_scores) / len(conflict_scores) scores = ragas_results.to_pandas().mean() production_score = ( scores["llm_context_precision_without_reference"] * 0.25 + scores["faithfulness"] * 0.30 + scores["answer_relevancy"] * 0.20 + conflict_free_rate * 0.25 ) return { "context_precision": round(float(scores["llm_context_precision_without_reference"]), 3), "context_recall": round(float(scores["llm_context_recall"]), 3), "faithfulness": round(float(scores["faithfulness"]), 3), "answer_relevancy": round(float(scores["answer_relevancy"]), 3), "conflict_free_rate": round(conflict_free_rate, 3), "production_score": round(production_score, 3), "production_ready": production_score >= 0.80, } # Interpretation thresholds # context_precision >= 0.80 → retriever is not injecting noise # faithfulness >= 0.85 → generator is grounded in retrieved context # conflict_free_rate >= 0.90 → most queries receive consistent context # production_score >= 0.80 → safe to promote to production
⚙️ 08 - Production Operations and Deployment
A conflict-aware RAG system in production requires careful attention to latency, cost, and operational monitoring. The conflict detection stage adds overhead - the question is how to contain that overhead while capturing the quality benefit.
- →Query embedding: ~5ms
- →Hybrid retrieval (vector + BM25): ~30ms
- →Cross-encoder re-ranking (top-20 → top-6): ~80ms
- →Conflict detection (Haiku-class model, 6 chunks): ~150ms
- →Generation (Sonnet-class, with conflict instruction): ~800ms
- →Total p95: ~1,100ms - within acceptable SLA for most use cases
- →Use a Haiku-class model for conflict detection - not Sonnet or Opus
- →Cache conflict analysis for identical chunk sets (query-independent)
- →Run detection only when precision scores fall below 0.7 threshold
- →Pre-index conflict metadata for known conflicting document pairs
- →Batch conflict detection asynchronously for non-real-time queries
Add conflict_detected_rate as a first-class dashboard metric alongside precision and faithfulness. A rising conflict_detected_rate is an early warning that your knowledge base has developed staleness, inconsistency, or data quality problems - visible weeks before it manifests as user-reported hallucinations. This metric is your data quality canary.
🛡️ 09 - Security, Governance, and Data Quality
The root cause of most knowledge conflicts in production is not a model problem or a retrieval architecture problem. It is a data governance problem. Gartner's February 2025 survey of 1,203 data management leaders found that 63% do not have or are unsure whether they have the right data management practices for AI. The fix is not a better retrieval layer - it is a governed knowledge base.
📊 10 - Measuring RAG Performance: The Right Metrics
⚠️ 11 - Common Anti-Patterns and How to Fix Them
🔭 12 - Conclusion and Future Directions
The hidden failure mode of RAG systems is now precisely diagnosed. It is not a retrieval problem. It is not a model problem. It is a context assembly problem: the pipeline hands conflicting context to the generator without any detection or resolution stage, and the generator makes an arbitrary choice between contradictory facts - confidently and invisibly, with no trace in your dashboards.
Five separate research efforts published between June 2025 and April 2026 - each independently arriving at the same architectural conclusion - form the strongest possible evidence base for what must be built next. What follows is a structured synthesis of what each paper found, what each tells you to build, and where the field is heading.
12.1 - The CONFLICTS Benchmark (Cattan, Jacovi et al., Google Research - June 2025)
The CONFLICTS benchmark is the paper that gave the field a shared language for the problem. Before this work, every team was solving slightly different versions of the same failure without a common taxonomy. Cattan et al. surveyed realistic enterprise RAG deployments and identified four structurally distinct conflict types that require fundamentally different resolution strategies - the taxonomy used throughout this article.
- →Freshness, opinion, complementary, and misinformation conflicts each produce different LLM failure modes - they cannot be handled by a single resolution strategy
- →Standard RAGAS metrics score all four conflict types the same way - no existing metric catches them
- →Google's production RAG systems encountered all four types at measurable rates on internal corpora
- →Misinformation conflicts (one source is factually wrong) are the rarest but the most dangerous - the model almost always picks the wrong answer
- →Add conflict type classification to your detection stage - a binary "conflict / no conflict" signal is insufficient
- →Implement source credibility tiers in your knowledge base - misinformation conflicts cannot be resolved without knowing which source is authoritative
- →Track conflict type distribution in your dashboards - a shift from freshness conflicts to misinformation conflicts is a governance emergency
- →Evaluate against the CONFLICTS benchmark suite before claiming production readiness
12.2 - CLEAR: Probing Latent Knowledge Conflict (Gao et al., October 2025)
CLEAR is the mechanistic paper. Where CONFLICTS classified conflict types from the outside, CLEAR probed inside the LLM's hidden states to understand exactly how transformer layers process conflicting context. Its three findings are the most important mechanistic results in RAG research in 2025 - and they have direct implications for system design.
| CLEAR Finding | What It Means | Design Implication |
|---|---|---|
| Hierarchical Knowledge Integration | Early transformer layers absorb retrieved context; later layers apply parametric memory override. The override is invisible at the output level. | LLM self-reported confidence is unreliable as a conflict signal. You need an external detector - the model cannot reliably introspect on why it chose one source over another. |
| Sentence-Level Conflict Signals | Conflicts manifest in hidden states at the sentence boundary level, not the document level. A document-level conflict detector misses the actual failure site. | Chunk at the sentence or paragraph level for conflict detection - not at the document level. The detector should operate on fine-grained units, not entire retrieved documents. |
| Parametric Amplification of Aligned Context | Irrelevant context that happens to align with pre-training knowledge is systematically amplified. The model will prefer stale training knowledge over fresher retrieved evidence when they partially conflict. | Freshness conflicts are systematically biased against the newer document. Explicit timestamp injection into the system prompt is necessary - position bias alone will not fix this. |
CLEAR's most counterintuitive finding: a retrieved document that disagrees with the model's pre-training knowledge is at a structural disadvantage - even when it is more recent, more authoritative, and more relevant. The model will not simply prefer the retrieved context. This is why freshness conflicts cannot be resolved by retrieval quality improvements alone. Your system prompt must explicitly instruct the model to prioritise the retrieved document over its own parametric memory when they conflict on temporal facts - and that instruction must be in the system prompt, not the user turn.
12.3 - TCR: Transparent Conflict Resolution (Ye et al., arXiv 2601.06842 - January 2026)
TCR is the state-of-the-art engineering paper. It does not just identify the problem - it provides a fully specified, empirically validated architectural solution with results across seven benchmarks. The three components of TCR collectively define the minimum viable conflict-aware RAG architecture for 2026.
Dual Contrastive Encoders
Separate encoders for semantic relevance and factual consistency - two signals that standard retrieval conflates into a single cosine score. A document can be highly semantically relevant and factually contradictory simultaneously. Disentangling these signals is the key architectural insight.
+5-18 F1 on conflict detection across 7 benchmarks
Self-Answerability Estimation
Before invoking retrieval, TCR queries the LLM's confidence in its own parametric memory for the input question. High self-answerability means the model should trust retrieved context less (it may override good evidence). Low self-answerability means the model should defer fully to retrieved context.
+21.4pp knowledge-gap recovery
Soft-Prompt Injection
Conflict signals are injected into the generator as lightweight soft prompts - continuous vector embeddings, not additional text tokens. This adds only 0.3% additional parameters with negligible inference overhead, avoiding the cost of a second LLM call for resolution guidance.
−29.3pp misleading-context overrides
Most engineering teams cannot implement TCR's soft-prompt injection layer without access to model weights. The production-viable approximation is the approach demonstrated in §06: use a fast Haiku-class model as an external conflict detector and inject its output as structured text into the system prompt of the generator. You capture approximately 60-70% of TCR's benefit at a fraction of the implementation cost. Self-answerability estimation is the TCR component most feasible to add without model fine-tuning - a pre-retrieval call asking "how confident are you in your parametric knowledge for this question?" can inform whether to trust retrieved context or escalate to a human.
12.4 - ICR: Internalized Conflict Resolution (Xiong et al., ScienceDirect - February 2026)
ICR represents a fundamentally different architectural philosophy from TCR and CLEAR. Rather than adding external detection modules between retrieval and generation, Xiong et al. train conflict resolution logic directly into the model using Direct Preference Optimization (DPO). The goal is a model that autonomously detects and resolves conflicts during normal inference - with no external pipeline stage required.
- xRequires access to model weights - cannot be applied to API-only deployments (Claude, GPT-4o, Gemini via API)
- xDPO training requires a curated preference dataset of conflict scenarios - expensive to build for domain-specific RAG
- xICR's 8-category conflict taxonomy may not transfer to niche enterprise domains without domain-specific fine-tuning
- xFine-tuned models require separate evaluation after each base model update - maintenance overhead that external detectors avoid
- ✓Zero latency overhead - conflict resolution is absorbed into the forward pass, eliminating the ~150ms detector call
- ✓No additional API cost per query - the detection stage costs nothing once training is done
- ✓ICR trained on TriviaQA and NQ achieves state-of-the-art without any architectural changes to the retrieval pipeline
- ✓The DPO preference pairs can be synthetically generated using the CONFLICTS benchmark - reducing the dataset construction cost significantly
ICR is the right architecture for teams deploying open-weights models (Llama 3, Mistral, Qwen) at scale who can afford the fine-tuning investment. For teams using API-only providers, the external detector pattern from §06 remains the only viable option. Watching whether Anthropic and OpenAI incorporate ICR-style conflict resolution into their API-accessible models in 2026-2027 is the key signal to monitor.
12.5 - ConflictQA: Cross-Source Conflicts Text vs. Knowledge Graph (Zhao et al., arXiv 2604.11209 - April 2026)
ConflictQA is the frontier paper that points to where enterprise RAG is heading, not where it is today. Most current RAG deployments retrieve from a single modality: unstructured text. But enterprise knowledge increasingly lives across two modalities simultaneously: unstructured documents (wikis, PDFs, policies) and structured knowledge graphs (product databases, compliance registries, entity relationship stores). ConflictQA is the first benchmark to address conflicts that arise specifically at the boundary between these two modalities.
Structured Fact vs. Unstructured Prose
A product database says a component's maximum voltage is 48V. An unstructured product manual (written before a revision) says 36V. The KG is authoritative; the document is stale. But the RAG system has no way to know which modality is more trustworthy for this fact type.
The Explanation-Based Thinking Approach
Zhao et al. find that standard CoT prompting fails on cross-source conflicts because it conflates the two resolution tasks: identifying the conflict and choosing between sources. Their key innovation is a two-stage process: first, explain why the conflict exists (the source of disagreement) - then reason about which source is more authoritative for the specific claim type.
Every enterprise RAG system that integrates a structured data source - a PostgreSQL product catalog, a Neo4j compliance graph, a Salesforce CRM - will encounter cross-modal conflicts. ConflictQA demonstrates that source modality must be a first-class input to your conflict detector, not just the content of the retrieved chunks. The detector needs to know: did this chunk come from a structured KG triple or from unstructured prose? That metadata changes which resolution strategy applies.
The 2025-2026 Research Convergence: Five Papers, One Architecture
Taken together, these five papers - CONFLICTS (Google, Jun 2025), CLEAR (Oct 2025), TCR (Jan 2026), ICR (Feb 2026), ConflictQA (Apr 2026) - form a complete specification for the next generation of production RAG. The convergence across independent research groups is unusually fast, suggesting the field is close to a stable consensus architecture.
| Paper | Primary Contribution | Key Number | Immediate Engineering Action |
|---|---|---|---|
| CONFLICTS (Jun 2025) | Taxonomy of 4 conflict types - shared vocabulary for the field | 4 distinct types, each needing a different resolution strategy | Implement 4-way conflict type classification in your detector |
| CLEAR (Oct 2025) | Mechanistic: how LLMs process conflicts in hidden states | Parametric amplification systematically biases against newer retrieved context | Add explicit "prefer retrieved over parametric for temporal facts" in system prompt |
| TCR (Jan 2026) | Full architecture: dual encoders + self-answerability + soft prompts | +21.4pp knowledge-gap recovery, −29.3pp misleading-context overrides | Implement self-answerability pre-check before retrieval |
| ICR (Feb 2026) | DPO fine-tuning to internalize conflict resolution in model weights | 8 conflict categories, state-of-the-art on TriviaQA + NQ | For open-weights deployments: fine-tune on synthetic CONFLICTS preference pairs |
| ConflictQA (Apr 2026) | Cross-modal (text vs. KG) conflict benchmark - the next frontier | Two-stage explanation-first resolution lifts accuracy +19% over CoT | Tag chunk source modality - apply higher trust to KG facts for numeric claims |
The Production Implementation Roadmap
claude-haiku-4-5-20251001 with structured output (see §06 implementation). Add conflict_detected_rate to your observability dashboard. Gate on conflict_free_rate ≥ 0.90 before promoting to production. Implement the resolution instruction map that routes each conflict type to the correct generator prompt.Build the Missing Stage - Or Inherit the Hidden Failure
Every RAG system that retrieves multiple documents will eventually encounter conflicting context. Five independent research groups - CONFLICTS, CLEAR, TCR, ICR, and ConflictQA - have now formally proven this, measured its impact, and specified the architectural solution. The research is unambiguous. The benchmarks exist. The tools are available.
The only question remaining is whether your pipeline has a mechanism to detect and resolve that conflict before it reaches the generator, or whether you are relying on the LLM to silently make the right choice. The LLM will not. It will confidently choose wrong - and your dashboards will show nothing out of the ordinary.
The fix is modular, measurable, and implementable in four weeks without touching the retrieval architecture or the generator model. Start with the conflict detector. Add conflict_free_rate as your fifth metric. Govern your knowledge base. Then, and only then, consider whether a model upgrade will move any needle.