RAG Isn’t Enough: Building the Context Layer That Actually Makes LLM Systems Work
RAG systems don’t fail at retrieval-they fail at context. As conversations grow, what enters the context window becomes the bottleneck. A context engine manages memory, compression, re-ranking, and token limits, making LLM systems reliable at scale.

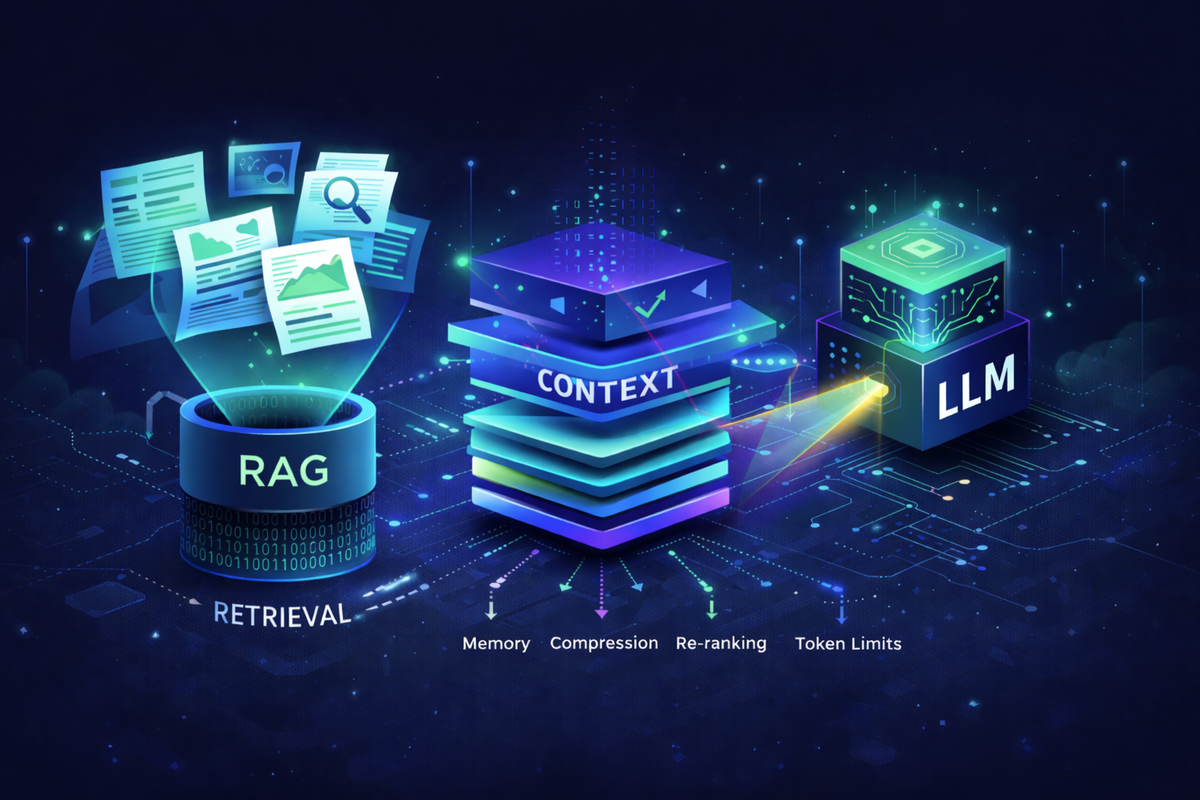
RAG Isn't Enough - I Built the Missing Context Layer That Makes LLM Systems Work
RAG systems break when context grows beyond a few turns. The real problem is not retrieval - it is what actually enters the context window. A context engine controls memory, compression, re-ranking, and token limits explicitly.
⚡ The Problem RAG Alone Cannot Solve
Most RAG tutorials teach you the same thing: embed your documents, store them in a vector database, retrieve the top-k chunks at query time, and pass them to an LLM. The pipeline works beautifully in a notebook. Then you put it in front of real users and something breaks in a way no chunking parameter can fix.
The conversation runs for ten turns. The user references something they said three exchanges ago. The retrieved documents are relevant, but they are competing with a growing backlog of conversation history for space in the context window. The model starts truncating. It loses the thread. It hallucinates a fact that contradicts a document it saw four turns ago. Your system has a context management problem, not a retrieval problem.
Research bears this out with a striking statistic: nearly 65% of enterprise AI failures in 2025 were attributed to context drift or memory loss during multi-step reasoning, not to model capability gaps. A 2024 survey by Gao et al. found that over 70% of errors in modern LLM applications stem from incomplete, irrelevant, or poorly structured context - not from insufficient model capability. The bottleneck in 2026 has shifted from the model side to the context side.
Andrej Karpathy put it precisely: "The LLM is the CPU, and the context window is the RAM." Just as an operating system curates what fits into RAM, a production LLM application needs a deliberate layer that controls what enters the context window, in what order, at what size. RAG fills the context window. A context engine manages it.
🔬 Context Engineering: A New Discipline
In June 2025, Andrej Karpathy published a now-famous post on X that crystallised what many production engineers had been building implicitly for months. He wrote: "Context engineering is the delicate art and science of filling the context window with just the right information for the next step."
He was deliberate about calling it both an art and a science. Science because it involves task descriptions, few-shot examples, RAG, state and history, compression, tool definitions - all of which can be measured and optimised. Art because it requires intuition about how LLMs allocate attention, how much context aids versus confuses, and what order information should appear in.
It is worth drawing sharp distinctions between the three overlapping concepts:
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step. Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and costs go up and performance comes down." - Andrej Karpathy, June 2025
As of March 2026, context engineering is no longer a standalone concept - it sits inside a broader agent stack that also includes agent harnesses, interoperability protocols (MCP), project memory for coding agents, and trace-first observability. The centre of gravity has shifted from "how to pack the best prompt" to "how agent systems manage runtime state, memory, tools, protocols, approvals, and long-horizon execution."
📅 The Three Generations of RAG Architecture
RAG is not a static pattern. It has evolved through three distinct architectural generations, each addressing the failures of the previous. Understanding this evolution explains why a naive RAG pipeline breaks in production - and what to build instead.
- Fixed-length chunks, converted to vectors, stored in a vector database
- Top-k retrieval by cosine similarity, concatenated directly as context
- Three core failures: semantic fragmentation during chunking, insufficient retrieval precision, no quality validation of retrieved results
- Works well for simple single-hop Q&A over a small, static knowledge base. Breaks for anything more complex.
- Query rewriting and step-back prompting to improve recall on ambiguous queries
- Hybrid search: combining semantic vector search with BM25/TF-IDF keyword search
- Cross-encoder re-ranking (BERT-based) to fix "lost in the middle" precision problems
- Parent-child chunking: retrieve small chunks for precision, expand to parent for context
- HyDE (Hypothetical Document Embeddings): generate a hypothetical answer, embed it, use that embedding to retrieve real documents - dramatically improves recall on sparse queries
- Agents autonomously determine whether retrieval is needed, and from which source
- Dynamic source selection: vector stores, knowledge graphs, web search, APIs - chosen at runtime based on query type
- Self-RAG: model decides when to retrieve, critiques its own outputs, retries when confidence is low
- GraphRAG (Microsoft): builds entity-relationship graphs over the corpus, enabling theme-level answers that naive RAG cannot produce
- Reflexion-style self-correction: agents verify answer correctness post-generation and re-retrieve if needed
🔗 Understanding RAG Architecture in Depth
Before building the context engine layer, you need a firm grip on what RAG actually does and where each component makes decisions that affect context quality. A production RAG pipeline is not a single step - it is a cascade of decisions, each of which compounds into the final context the model sees.
Stage 1: Chunking Strategy
How you split your documents determines the fundamental granularity of information available for retrieval. The three canonical approaches have distinct trade-offs:
| Strategy | Mechanism | Strengths | Weaknesses | Best For |
|---|---|---|---|---|
| Character Split | Splits strictly by character count with optional overlap | Fast, deterministic, zero dependencies | Can cut words, sentences, or paragraphs mid-thought, destroying semantic coherence | Structured data, logs, code |
| Recursive Split | Tries paragraph → sentence → word boundaries in sequence | Preserves semantic units, the default choice for prose | Inconsistent chunk sizes, poor on highly structured documents | General prose, articles, docs |
| Token Split | Splits on LLM tokenizer vocabulary (tiktoken) | Guarantees chunks fit context windows exactly, no overflow surprises | Computationally expensive, may ignore semantic boundaries | Context-window-constrained pipelines |
| Semantic Split | Embeds sentences, splits on embedding similarity drops | Best semantic coherence, topic-aware boundaries | Slow (requires embedding every sentence), variable chunk sizes | High-precision retrieval over long docs |
| Parent-Child | Index small chunks for retrieval, expand to parent for context | High precision retrieval + rich context for generation | Increased storage, more complex indexing pipeline | Long documents, technical manuals |
| AST-based (Code) | Parses code along semantically meaningful AST boundaries | Preserves function, class, module boundaries exactly | Language-specific, embedding search degrades at codebase scale | Code repositories, APIs, SDKs |
Stage 2: Hybrid Retrieval and Reciprocal Rank Fusion
Pure semantic (vector) retrieval casts a wide net but produces imperfect rankings. Relevant documents frequently end up "lost in the middle" of the result list. Production systems in 2026 combine two complementary signals: semantic embeddings (high recall, concept-level) and BM25/TF-IDF keyword matching (high precision, exact terminology). The scores are fused via Reciprocal Rank Fusion (RRF), which combines rankings without requiring score normalisation.
from langchain_community.vectorstores import Chroma from langchain_community.retrievers import BM25Retriever from langchain.retrievers import EnsembleRetriever from langchain_openai import OpenAIEmbeddings # Build both retrieval backends from the same documents docs = load_documents() # your document loading logic # Semantic retriever - captures concept-level relevance vectorstore = Chroma.from_documents(docs, embedding=OpenAIEmbeddings()) semantic_retriever = vectorstore.as_retriever(search_kwargs={"k": 25}) # Keyword retriever - captures exact terminology and proper nouns bm25_retriever = BM25Retriever.from_documents(docs) bm25_retriever.k = 25 # EnsembleRetriever applies Reciprocal Rank Fusion automatically. # weights=[0.6, 0.4] means semantic scores weighted slightly higher. # Tune toward 0.4/0.6 for keyword-heavy technical queries. hybrid_retriever = EnsembleRetriever( retrievers=[semantic_retriever, bm25_retriever], weights=[0.6, 0.4] ) # Returns fused, deduplicated results - typically top 15-20 candidates candidates = hybrid_retriever.invoke("What is the difference between RAG and fine-tuning?")
⚙️ Context Engine: The Missing Layer
The context engine sits between retrieval output and the final prompt construction. Its job is to make explicit what naive RAG leaves implicit: exactly what information enters the context window, at what size, in what order, within a strict token budget. Without this layer, your system's behaviour under pressure (long conversations, noisy retrieval, latency constraints) is undefined.
Token Budget Allocation
Every context window has a fixed size. A context engine must make explicit allocation decisions before construction, not discover overflow at inference time. A practical allocation for a 128K token window looks like this:
| Context Slot | Default Allocation | Notes |
|---|---|---|
| System prompt | 5% (~6K tokens) | Instructions, persona, output format, tool descriptions. Fixed size, highest priority. |
| Recent conversation history | 20% (~25K tokens) | Last N turns verbatim. Do not compress. Recency matters most for coherence. |
| Summarised history | 10% (~13K tokens) | LLM-generated rolling summary of older turns. Updated asynchronously to avoid latency. |
| Retrieved documents | 45% (~58K tokens) | Re-ranked, compressed, deduplicated retrieval results. Largest slot - where RAG lives. |
| User message + output reserve | 20% (~26K tokens) | Current turn input plus headroom for the model's response. Never sacrifice this. |
import tiktoken from dataclasses import dataclass, field from typing import Optional enc = tiktoken.get_encoding("cl100k_base") def count_tokens(text: str) -> int: return len(enc.encode(text)) @dataclass class ContextBudget: total_tokens: int = 128_000 system_prompt_pct: float = 0.05 recent_history_pct: float = 0.20 summary_pct: float = 0.10 documents_pct: float = 0.45 output_reserve_pct: float = 0.20 def docs_budget(self) -> int: return int(self.total_tokens * self.documents_pct) def history_budget(self) -> int: return int(self.total_tokens * (self.recent_history_pct + self.summary_pct)) class ContextEngine: def __init__(self, budget: ContextBudget): self.budget = budget def build_context( self, system_prompt: str, history_turns: list[dict], retrieved_docs: list[str], user_query: str, summary: Optional[str] = None ) -> dict: # 1. Allocate doc budget and compress if needed doc_budget = self.budget.docs_budget() docs_ctx, compression_ratio = self._fit_documents(retrieved_docs, doc_budget) # 2. Allocate history budget: recent verbatim + rolling summary hist_budget = self.budget.history_budget() hist_ctx = self._fit_history(history_turns, summary, hist_budget) return { "system": system_prompt, "context": docs_ctx, "history": hist_ctx, "query": user_query, "compression_ratio": compression_ratio, "tokens_used": count_tokens(docs_ctx + hist_ctx), } def _fit_documents(self, docs: list[str], budget: int) -> tuple[str, float]: # Pack documents greedily until budget is exhausted selected, total = [], 0 for doc in docs: tokens = count_tokens(doc) if total + tokens <= budget: selected.append(doc) total += tokens else: break # never overflow - hard budget ceiling original_tokens = sum(count_tokens(d) for d in docs) ratio = 1 - (total / original_tokens) if original_tokens > 0 else 0 return "\n\n---\n\n".join(selected), ratio def _fit_history(self, turns: list[dict], summary: Optional[str], budget: int) -> str: # Always include summary first (if present), then most-recent turns parts, used = [], 0 if summary: s_tokens = count_tokens(summary) if s_tokens <= budget // 3: # cap summary at 1/3 of history budget parts.append(f"[Summary of prior conversation]\n{summary}") used += s_tokens # Add recent turns newest-first, stop when budget exhausted for turn in reversed(turns): text = f"{turn['role']}: {turn['content']}" t = count_tokens(text) if used + t > budget: break parts.insert(1 if summary else 0, text) used += t return "\n".join(parts)
💾 Memory Systems: In-Session vs Cross-Session
Memory in LLM systems is not a single concept - it is three distinct problems requiring three distinct architectures. Conflating them is one of the most common design mistakes in production systems.
📉 Compression Strategies and Token Budgets
When conversation history and retrieved documents together exceed the available token budget, the system must compress rather than truncate blindly. The difference matters: truncation discards arbitrarily. Compression preserves meaning at lower token cost. There are four production-grade compression strategies:
- →Maintain a running LLM-generated summary of older turns
- →Update asynchronously after each turn to avoid latency on the hot path
- →Keep last N turns verbatim, summarise everything before that
- →Cost: one LLM call per update (background job, not blocking)
- →Graph-based sentence ranking, zero LLM calls needed
- →Identifies most informative sentences by co-occurrence weight
- →Achieves 40-60% reduction with ~85% semantic retention
- →Use for retrieved document compression, not conversation history
In the reference implementation (800-token budget, 5 documents, multi-turn conversation): Turn 1 (no history) - 48% compression applied to documents, all 5 retrieved docs fit. Turn 5 (4 prior turns in memory) - compression tightens automatically to 55% as history consumes more budget. The model always receives a coherent, non-overflowing context. The system adapts; it never fails silently with a token overflow error.
🏆 Re-ranking: Fixing Lost-in-the-Middle
Vector search maximises recall: it finds everything that might be relevant. The problem is that relevance at position #7 is just as invisible to the model as irrelevance at position #3. LLMs systematically attend less to information buried in the middle of long contexts - a well-documented phenomenon called "lost in the middle."
Re-ranking solves this by introducing a second-stage model that examines query-document pairs holistically. Cross-encoders (like BERT-based cross-attention models, Cohere Reranker, or ColBERT) evaluate relevance far more accurately than cosine similarity because they see the full text of both the query and the document simultaneously - not just their compressed embeddings.
After re-ranking, how you order chunks in the context window matters as much as which chunks you selected. Anthropic's long context usage guide explicitly advises placing the most critical information at the beginning or end of the context. Never bury the most relevant retrieved document in the middle of a long context block - the model's attention there is systematically weaker.
🔎 Advanced Retrieval Patterns for Production
HyDE: Hypothetical Document Embeddings
Standard retrieval embeds the user's query and finds documents with similar embeddings. The problem: user queries are short, underspecified, and semantically far from the dense prose of the documents they are looking for. HyDE inverts this: it asks the LLM to generate a hypothetical answer to the query, then embeds that hypothetical answer and uses that richer embedding for retrieval. The hypothetical document is in the same semantic space as real documents, dramatically improving recall on sparse or ambiguous queries.
from langchain_core.prompts import ChatPromptTemplate from langchain_anthropic import ChatAnthropic from langchain_core.output_parsers import StrOutputParser from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings llm = ChatAnthropic(model="claude-haiku-4-5") # cheap model for hypothesis generation embeddings = OpenAIEmbeddings() vectorstore = Chroma("my_index", embeddings) # Step 1: Generate a hypothetical document that would answer the query hypothesis_prompt = ChatPromptTemplate.from_template("""Write a short factual paragraph that would be a perfect answer to the following question. Be specific and detailed - do not hedge or say 'I don't know'. Question: {query} Hypothetical answer:""") generate_hypothesis = hypothesis_prompt | llm | StrOutputParser() def hyde_retrieve(query: str, k: int = 10) -> list: # Generate hypothetical document - used only for embedding, never shown to user hypothesis = generate_hypothesis.invoke({"query": query}) # Retrieve using the hypothesis embedding (semantically richer than query alone) results = vectorstore.similarity_search_by_vector( embeddings.embed_query(hypothesis), k=k ) return results # Usage: sparse or ambiguous query benefits most from HyDE # "What causes context rot in transformer models?" # → hypothesis: detailed technical paragraph about attention dilution # → retrieves docs that mention attention, context window, dilution # → much better than embedding the 8-word query directly results = hyde_retrieve("What causes context rot in transformer models?")
GraphRAG: Entity-Relationship Retrieval
Standard vector retrieval excels at pinpoint facts ("What does X mean?") but struggles with global questions ("What themes emerge across this entire corpus?"). GraphRAG, first demonstrated by Microsoft in 2024, builds an entity-relationship graph over the corpus during indexing. At query time, it traverses the graph rather than searching by embedding similarity, enabling theme-level and relationship-level answers with full traceability.
Naive RAG
Answers pinpoint facts from the closest matching chunk. Fails on cross-document themes or relationships.
local queries onlyGraphRAG
Builds entity-relationship graph at index time. Traverses graph for theme-level, global, and relationship queries.
local + global queriesSelf-RAG
Model decides when to retrieve, critiques its own outputs, and retries when confidence falls below threshold.
adaptive retrievalAgentic RAG
LLM agent plans multi-step retrieval, selects sources dynamically, self-verifies answers post-generation.
fully autonomousHyDE
Generate hypothetical answer, embed it, retrieve against that richer embedding. Best for sparse/ambiguous queries.
recall improvementParent-Child
Index small chunks for high-precision retrieval. Expand to parent chunks at generation time for full context.
precision + context🤖 Agentic RAG and the Karpathy Pattern
In April 2026, Andrej Karpathy published a GitHub Gist describing an architectural pattern that drew immediate attention as a potential successor to both naive RAG and vector database approaches for personal and team knowledge management. He called it an LLM Knowledge Base - a persistent, agent-maintained wiki.
The core thesis: instead of using an LLM to perform just-in-time retrieval from a static pool of raw documents, deploy an LLM agent to proactively and continuously compile those documents into a persistent, interconnected, structured knowledge base - a wiki. The heavy cognitive work of reading, extracting entities, identifying relationships, and synthesising conclusions happens once at ingestion. Subsequent queries operate on curated knowledge, not raw documents.
- xRe-discovers knowledge on every query from scratch
- xWasted compute: same relationships re-derived each time
- xNo cross-document synthesis at indexing time
- x"Amnesiac" - forgets what it concluded last time
- xQuality bounded by retrieval precision at query time
- ✓Agent compiles knowledge once, continuously refines it
- ✓Relationships and syntheses stored in a persistent graph
- ✓Cross-document entities linked at ingestion, not query time
- ✓Queries answer from curated Markdown wiki, not raw docs
- ✓Works at ~100 articles / ~400K words without vector infra
Karpathy's original implementation is built for personal use (Obsidian, local Markdown files). The community has been quick to identify the gap: scaling to enterprise environments with thousands of employees, millions of records, and tribal knowledge that contradicts itself across teams requires server-side, transactional, and secure knowledge layer infrastructure. Epsilla's Semantic Graph and similar enterprise products are the current direction. The principle - compile once, query from structure - is sound. The implementation must be adapted for production.
📊 Measurement, Evaluation, and LLM-as-Judge
A context engineering pipeline without measurement is guesswork. Production RAG systems require systematic evaluation across four dimensions: retrieval quality, generation accuracy, system latency, and token cost. In 2026, LLM-as-judge has become the dominant approach for automated quality evaluation, supplementing but not replacing human annotation for high-stakes deployments.
from langchain_anthropic import ChatAnthropic from langchain_core.prompts import ChatPromptTemplate from pydantic import BaseModel, Field from typing import Literal class RAGEvalResult(BaseModel): faithfulness: Literal["yes", "no", "partial"] = Field( description="Does the answer contain only facts from the provided context?" ) relevance: int = Field(ge=1, le=5, description="1=irrelevant, 5=perfectly relevant") completeness: int = Field(ge=1, le=5, description="1=major gaps, 5=fully addresses question") explanation: str = Field(description="One sentence explanation of the scores") eval_prompt = ChatPromptTemplate.from_template("""You are an expert evaluator for RAG systems. Given a question, a retrieved context, and a generated answer, evaluate the answer. Question: {question} Retrieved Context: {context} Generated Answer: {answer} Evaluate faithfulness (does the answer stick to context?), relevance, and completeness. Return valid JSON matching the schema.""") # Use claude-sonnet for evaluation (strong reasoning), haiku for generation (cost) judge_llm = ChatAnthropic(model="claude-sonnet-4-5").with_structured_output(RAGEvalResult) evaluator = eval_prompt | judge_llm def evaluate_answer(question: str, context: str, answer: str) -> RAGEvalResult: return evaluator.invoke({ "question": question, "context": context, "answer": answer }) # Run evaluation over your test set results = [evaluate_answer(q, c, a) for q, c, a in test_cases] avg_faithfulness = sum(1 for r in results if r.faithfulness == "yes") / len(results) avg_relevance = sum(r.relevance for r in results) / len(results) print(f"Faithfulness: {avg_faithfulness:.1%} Relevance: {avg_relevance:.2f}/5")
🛡 Security, Governance, and Anti-Patterns
ConversationBufferMemory and ConversationChain encourage this pattern and are now deprecated.SqliteSaver or PostgresSaver checkpointers manage this per thread_id automatically. Trim with trim_messages() from langchain_core to enforce a hard token ceiling before every LLM call.max_tokens ceiling in your context construction, not in your prompt. Use tiktoken to count tokens before constructing the final payload. Emit a context_utilisation_pct metric to your observability stack; alert at >85%.⚖️ Choosing the Right Architecture
The right context architecture depends on your workload topology, latency budget, and knowledge base characteristics. The table below maps the key decision axes to the architectural pattern that performs best.
| Workload Type | KB Size | Query Pattern | Architecture | Why |
|---|---|---|---|---|
| Single-turn Q&A | <10K docs | Pinpoint facts | Naive RAG | Pipeline overhead unjustified. Simple LCEL chain with top-k retrieval is sufficient. |
| Multi-turn chatbot | Any | Context-dependent | Context Engine | Memory accumulation and token budget management become critical after turn 3. |
| Enterprise search | >100K docs | Mixed precision/recall | Advanced RAG | Hybrid retrieval + cross-encoder re-ranking required for acceptable precision at scale. |
| Thematic analysis | Corpus-level | Global questions | GraphRAG | Entity relationships needed for cross-document theme queries. Vector retrieval alone fails. |
| Research assistant | ~100 articles | Synthesis + recall | Karpathy Pattern | Agent-maintained wiki eliminates repeated re-derivation. Works without vector infrastructure. |
| Autonomous agent | Dynamic | Multi-step reasoning | Agentic RAG | Agent selects sources, retries on low confidence, self-verifies post-generation. |
| Full codebase reasoning | Entire repo | Cross-file dependency | Long Context | Entire codebase processing provides clear value where AST + embedding search fails at scale. |
The context engine doesn't decide what to retrieve. It decides what the model actually sees. That distinction - between retrieving information and managing the context that shapes reasoning - is the architectural insight that separates production systems from demos.
Build the Missing Layer
RAG systems break when context grows beyond a few turns - not because retrieval fails, but because nothing is managing what enters the context window. A context engine is not a luxury; it is the component that converts a demo into a production system.
The practical path: start with hybrid retrieval and a cross-encoder re-ranker. Add explicit token budget allocation. Implement rolling summarisation for history. Instrument context_utilisation_pct and faithfulness scores from day one. For theme-level queries, evaluate GraphRAG. For agent-maintained knowledge, evaluate the Karpathy Pattern.
The context engineering discipline is still maturing - but the core insight is durable: the critical bottleneck has shifted from model capability to context quality. Engineers who build the layer that controls what the model sees will build the systems that actually work.