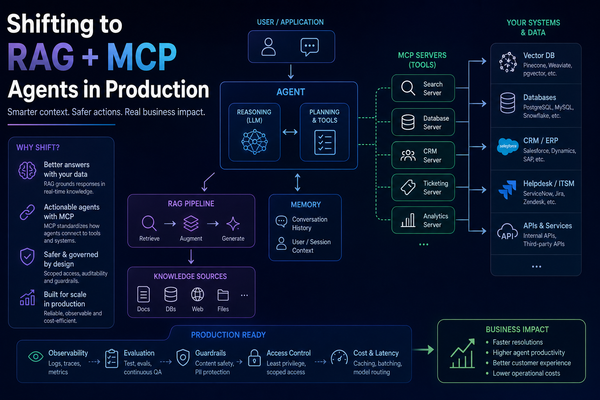
Agentic AI: Revolutionizing Automation with Autonomous Agents
Agentic AI transforms automation by enabling autonomous agents to reason, plan, and act independently. By combining advanced models, real-time data, and adaptive memory, it supports dynamic workflows, enhances decision-making, and drives efficient, scalable, and intelligent systems.
Agentic AI & LLM Pipelines - From Chatbots to Autonomous Systems
AI Automation · Agentic Systems · LLM Pipelines
Agentic AI & LLM Pipelines
From simple chatbots to fully autonomous systems capable of planning, reasoning, and acting - agentic AI represents the next architectural leap in how we build software powered by language models. Now with a complete demystification of LLM vs RAG vs AI Agent vs Agentic AI vs MCP.
TOPIC Agentic AI Systems
LEVEL Senior Practitioner
READ TIME ~32 min
UPDATED April 2026
⚡ The Shift from Chatbot to Agent
Most organizations' first exposure to LLMs was a chatbot - a system that takes a message, calls an API, and returns a response. Clean, stateless, predictable. Useful, but fundamentally limited: the model reads, it generates, and then it stops. It cannot go find information it does not have. It cannot execute code. It cannot book a meeting, check a database, or run a shell command. It can only produce text about doing those things.
An agent is something categorically different. An agent receives a goal, breaks it into steps, decides which tools to invoke, executes those tools, observes the results, adjusts its plan, and repeats - until the goal is reached or it determines it cannot be reached. The LLM is still at the center, but now it is the reasoning engine inside a larger system that can actually interact with the world.
The distinction matters because it changes what you can build. A chatbot can help someone draft an email. An agent can read your inbox, identify the urgent threads, draft responses tailored to each sender's history and your stated priorities, and flag the ones that need human judgment - without you specifying each step.
! Classic LLM Chatbot
x Single-turn or multi-turn conversation only
x No access to external tools or APIs
x Knowledge frozen at training cutoff
x Cannot execute code or interact with systems
x No memory beyond the context window
x Cannot decompose goals into sub-tasks
x Human must orchestrate every step explicitly
+ Agentic LLM System
v Goal-driven, multi-step autonomous execution
v Tool calling: APIs, code execution, web search
v Real-time information via retrieval and search
v Can trigger actions in external systems
v Short, long, and semantic memory layers
v Hierarchical task decomposition and planning
v Human oversight at defined intervention points
💡 The Key Insight
The LLM's role in an agentic system is not to generate a final answer - it is to be the reasoning and decision engine within a feedback loop. The model decides what to do next, the environment executes it, and the model observes the result. This loop continues until completion. That loop is the fundamental architectural primitive of every agentic system.
🧠 Core Architecture of an LLM Agent
Every agent, regardless of the framework or LLM underneath, is built from the same five components. Understanding these components - and how they interact - is the prerequisite for designing agents that actually work in production.
LLM Core
The language model that performs all reasoning, planning, and decision-making. It reads the current state (context, tool results, memory), decides the next action, and generates the output that drives execution. GPT-4o, Claude Sonnet, Llama 3.1, and Gemini 1.5 Pro are the most common choices at the time of writing.
Tool Registry
The set of functions, APIs, and capabilities the agent can invoke. Each tool has a name, a description (which the model reads to decide when to use it), and an input schema. The model generates a structured call; the orchestration layer executes it and returns the result.
Memory System
Storage that persists information across steps and sessions. Includes the short-term context window (what the model currently sees), long-term storage (a database the model can write to and query), and semantic/vector memory (embeddings that allow approximate similarity search over past knowledge).
Planner
The component that decomposes a high-level goal into a sequence of achievable steps. In simple agents this is implicit - the LLM just decides the next action at each turn. In more sophisticated systems, a dedicated planning step generates an explicit plan before execution begins.
Orchestrator
The control loop that ties everything together: passes context to the LLM, routes tool calls to the correct executors, handles errors and retries, manages the termination condition, and decides when to involve a human. This is typically implemented in the agent framework (LangGraph, AutoGen, etc.).
// Core Agent Execution Loop
🎯
Goal Input
User or system provides task
→
🧠
LLM Reasoning
Decide next action
→
🔧
Tool Call
Execute or skip
→
👀
Observation
Parse tool result
→
✅
Goal Reached?
End or loop back
🔄 ReAct: Reasoning + Acting in Practice
ReAct (Reasoning + Acting) is the most widely used prompting pattern for LLM agents. Originally described in a 2022 paper from Google Brain and Princeton, it interleaves Thought (the model's internal reasoning about what to do), Action (the tool call the model decides to make), and Observation (the result returned by the tool). This interleaving is the key insight: by forcing the model to reason explicitly before acting and to reflect on observations before the next action, you get significantly more reliable multi-step behavior than simply asking the model to output a final answer.
ReAct Pattern - Pseudo-trace
# Goal: "Find the current CEO of Anthropic and their LinkedIn URL"Thought: I need to find who the current CEO of Anthropic is.
I'll use the web search tool to get current information.
Action: web_search(query="Anthropic CEO 2025")
Observation:"Dario Amodei is the CEO and co-founder of Anthropic..."Thought: I have the name. Now I need their LinkedIn profile URL.
I should search specifically for that.
Action: web_search(query="Dario Amodei LinkedIn profile")
Observation:"linkedin.com/in/darioamodei - Dario Amodei..."Thought: I now have both pieces of information. Goal complete.
Final Answer: Dario Amodei, linkedin.com/in/darioamodei
The practical implementation of ReAct in modern frameworks is straightforward: the system prompt instructs the model to follow the Thought / Action / Observation format, the orchestrator parses the model's output for action calls, executes them, and appends the observation to the conversation before calling the model again. The loop continues until the model produces a "Final Answer" token or a similar termination signal.
ReAct vs Chain-of-Thought vs Simple Tool Use
It is worth distinguishing ReAct from related patterns. Chain-of-Thought (CoT) prompting asks the model to reason step by step before answering, but without tool calls - it reasons, but cannot act. Simple tool use (function calling) allows the model to call tools, but without the explicit reasoning trace - it can act, but the reasoning is opaque and harder to debug. ReAct combines both: explicit reasoning traces that are auditable and debuggable, paired with the ability to take actions and update reasoning based on observations.
For production agentic systems, the reasoning trace is not just a nice-to-have - it is a critical operational artifact. When an agent produces a wrong answer or takes an unexpected action, the Thought trace is your primary debugging tool.
🔧 Tool Use: Giving Agents Hands
Tools are what separate agents from chatbots. A tool is any function the agent can call to interact with the external world - a web search API, a code interpreter, a database query, a REST API call, a file read/write, a browser automation step, an email send. The LLM does not execute the tool directly; it generates a structured description of what it wants to call and with what arguments, and the orchestration layer handles the actual execution.
The design of your tool schemas is one of the most impactful decisions in agent development. Models are surprisingly sensitive to tool descriptions: a tool named get_data with a vague description will be used inconsistently; a tool named query_customer_support_tickets with a precise description of what it returns and when to use it will behave predictably. Writing tool descriptions is, in practice, a form of prompt engineering.
Implementing Tool Calling with the Anthropic API
Python - Tool Definition and Calling
import anthropic
import json
client = anthropic.Anthropic()
# Define tools with precise descriptions
tools = [
{
"name": "web_search",
"description": "Search the web for current information on a topic. ""Use when you need facts that may have changed after training, ""or when you need to verify specific claims.",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query string"
}
},
"required": ["query"]
}
},
{
"name": "run_python",
"description": "Execute Python code and return stdout/stderr. ""Use for calculations, data processing, or file operations.",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "Python code to execute"}
},
"required": ["code"]
}
}
]
# The agent loopdefrun_agent(goal: str, max_iterations: int = 10):
messages = [{"role": "user", "content": goal}]
for _ in range(max_iterations):
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
tools=tools,
messages=messages
)
if response.stop_reason == "end_turn":
return response.content[0].text
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = execute_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
⚠️ Tool Design Warning
Never give an agent a tool it should not use autonomously without a human checkpoint. A tool that can DELETE FROM users or send_email_to_all_customers should have an explicit confirmation step. Agents that can take irreversible actions need hard guardrails, not just good system prompts.
💾 Memory Systems: Short, Long, and Semantic
Memory is the component most developers underestimate when they first build agents. The default approach - jam everything into the context window and hope it fits - works fine for demos and breaks immediately at production scale. A thoughtful memory architecture is what separates a prototype from a system that actually handles real workloads over time.
📋
In-Context Memory
The model's current context window - conversation history, tool results, instructions. Fast and directly accessible but limited in size (typically 128K-200K tokens). Everything here is lost when the session ends.
🗄️
External Long-Term Memory
A database the agent can read and write to persist information across sessions. Can be a key-value store for structured facts, a relational DB for complex data, or a document store for unstructured notes.
🔍
Semantic / Vector Memory
Embeddings stored in a vector database (Pinecone, Weaviate, Chroma). Allows the agent to retrieve relevant past information by semantic similarity rather than exact key lookup - essential for large knowledge bases.
⚡
Episodic Memory
A structured log of past agent runs: what goal was given, what steps were taken, what worked, what failed. Used for self-improvement and for avoiding repeated mistakes across sessions.
🗺️ Planning and Multi-Step Reasoning
Simple ReAct agents decide their next action one step at a time. This works well for tasks with a clear linear path, but struggles with complex goals that require branching, parallel execution, or backtracking. For these cases, explicit planning - generating a full task decomposition before beginning execution - dramatically improves both reliability and efficiency.
The Plan-and-Execute Pattern
In Plan-and-Execute, the agent makes two separate LLM calls: first, a planning call that generates a structured list of steps to complete the goal; second, an execution loop that works through those steps, updating the plan if circumstances change. The planner and executor can use different models - a larger, more expensive model for planning, a smaller and faster model for routine execution steps.
Python - Plan-and-Execute Agent
import json
from anthropic import Anthropic
client = Anthropic()
PLANNER_SYSTEM = """You are a planning agent. Given a goal, decompose it into
concrete, executable steps. Return ONLY a JSON array of steps.
Each step: {"id": int, "description": str, "tool": str|null, "depends_on": [int]}"""defplan(goal: str) -> list[dict]:
response = client.messages.create(
model="claude-sonnet-4-5", # Bigger model for planning
max_tokens=2048,
system=PLANNER_SYSTEM,
messages=[{"role": "user", "content": goal}]
)
return json.loads(response.content[0].text)
defexecute_step(step: dict, completed_results: dict) -> str:
context = "\n".join(
f"Step {sid} result: {res}"for sid, res in completed_results.items()
)
response = client.messages.create(
model="claude-haiku-4-5", # Smaller model for execution
max_tokens=1024,
tools=tools,
messages=[{"role": "user",
"content": f"Previous results:\n{context}\n\nExecute: {step['description']}"}]
)
return response.content[0].text
defplan_and_execute(goal: str) -> str:
steps = plan(goal)
results = {}
for step in steps:
ifall(dep in results for dep in step["depends_on"]):
results[step["id"]] = execute_step(step, results)
return results[steps[-1]["id"]]
🤝 Multi-Agent Architectures
A single agent with a general-purpose system prompt will hit reliability and capability ceilings. The solution that has emerged in practice is multi-agent systems: networks of specialized agents, each with a focused role, coordinated by an orchestrator.
🏗️
Hierarchical (Orchestrator + Workers)
A central orchestrator agent receives the goal, decomposes it, and delegates sub-tasks to specialized worker agents. Workers report results back to the orchestrator, which synthesizes a final answer.
🔗
Sequential Pipeline
Agents arranged in a chain: each agent takes the output of the previous as input, transforms or enriches it, and passes it forward. Best for processing pipelines: extract → analyze → validate → format.
🌐
Collaborative / Debate
Multiple agents work on the same problem from different angles, critique each other's outputs, and converge on a consensus answer. More expensive but produces significantly higher-quality results for complex reasoning tasks.
// Multi-Agent Content Pipeline - Production Pattern
Cross-references claims across sources. Flags contradictions
✍️
AGENT 3
Writer Agent
Drafts article from verified facts + style guidelines
🔍
AGENT 4
Editor Agent
Reviews for clarity, tone, accuracy. Returns critique + revised draft
🚀
PUBLISH
Formatter
Converts to target format (HTML, Markdown) + posts via API
⚖️ Framework Comparison: LangGraph vs AutoGen vs CrewAI
Framework
Model
Best For
Tradeoffs
Status
LangGraph
Stateful graph of nodes and edges. You define the execution graph explicitly - nodes are functions, edges are transitions, state is typed.
Complex workflows requiring precise control over execution order, conditional branching, cycles, and human-in-the-loop checkpoints.
Higher upfront complexity. Steep learning curve. Verbose for simple use cases.
Production
AutoGen (Microsoft)
Conversational multi-agent framework. Agents communicate via messages. Orchestration emerges from conversation patterns rather than explicit graphs.
Multi-agent collaboration, debate, and critique patterns. Code-writing and execution workflows.
Harder to predict execution order. Conversational overhead increases cost.
Maturing
CrewAI
Role-based agent crew. Define agents with personas, assign tasks, let the crew collaborate.
Rapid prototyping. Business process automation with role-oriented thinking.
Less fine-grained control than LangGraph. Abstraction can hide important execution details.
Growing
Anthropic SDK (native)
Direct tool use + message loop. No framework - just the raw API with tool calling and structured outputs.
Maximum control and minimum abstraction. Simple agents where framework overhead is not justified.
More code to write. No built-in state management or retry logic.
Recommended for start
🏭 Real-World Implementations
The most important thing to understand about production agentic systems is that the interesting work is almost never in the LLM call itself. It is in the surrounding infrastructure: the tool definitions, the state management, the error handling, the human escalation paths, and the observability layer.
Case 1: Autonomous Customer Support Triage (ServiceNow Pattern)
ServiceNow's AI agent handles the first tier of IT incident management. When a ticket arrives, the agent reads the description, queries the knowledge base for similar past incidents and their resolutions, checks the configuration management database for the affected system's dependencies, and either resolves the ticket automatically with a documented action, or escalates with a pre-populated resolution recommendation for a human engineer. The key design decision: the agent has read access to the CMDB and knowledge base, but write access only to update ticket status and add notes - it cannot modify system configurations directly.
Case 2: Code Review and Security Scanning Pipeline
Typical failure rate for unmonitored agent deployments in the first month, due to unexpected tool errors, context overflow, and prompt regressions from model updates.
3-5x
Cost vs Estimate
Teams consistently underestimate token consumption in agentic systems. Loops, retries, and large context windows compound. Always measure in production before setting budgets.
P99 Latency
The Real SLA Metric
Average latency in agents is misleading. Design with explicit step limits and timeout budgets, and monitor the distribution, not just the mean.
Trace ID
Most Important Artifact
Every agent run should have a unique trace ID propagated across every LLM call, tool execution, and state transition. Without it, production incidents become undebuggable.
🔒 Security and Safety Considerations
🚨 Prompt Injection
The most dangerous vulnerability in agentic systems. A malicious actor embeds instructions in content that the agent will read - a web page it searches, a document it processes, an email it retrieves. Defenses include output validation layers, sandboxed tool execution, and treating all external content as untrusted regardless of source.
⚠️ Privilege Escalation via Tool Chaining
An agent with access to multiple tools can sometimes combine them in ways that exceed its intended permissions. Model every tool combination as a potential permission boundary, not just individual tools in isolation.
⚠️ Uncontrolled Resource Consumption
An agent in a loop can exhaust API quotas, fill databases, saturate downstream services, or run up enormous LLM bills before any human notices. Always set explicit resource budgets: maximum steps, maximum tokens, maximum tool calls per run.
⛔ Anti-Patterns to Avoid
! The "One Big System Prompt" Agent
Trying to make a single agent handle every possible task by stuffing all instructions, tools, and context into one massive system prompt. The result is an agent that is mediocre at everything and excellent at nothing.
Design specialized agents for distinct task types. An agent whose sole purpose is to write SQL queries, with a focused system prompt and only database-related tools, will dramatically outperform a general-purpose agent attempting the same task.
! Trusting Agent Output Without Validation
Taking the agent's final output and passing it directly to a downstream system without any validation layer. LLMs hallucinate, format outputs incorrectly, and occasionally produce confidently wrong answers.
Add structured output schemas and validation at every agent exit point. Use Pydantic models or JSON Schema validation. For high-stakes outputs, add a dedicated verification agent that checks the primary agent's work before it is acted upon.
! No Maximum Step Limit
Deploying an agent without a hard cap on the number of steps it can take. When an agent encounters an unexpected state it can loop indefinitely, burning tokens and potentially causing side effects with each iteration.
Always set a hard maximum step count (typically 10-20 for simple agents, up to 50 for complex research tasks). When the limit is hit, return whatever partial result exists with a clear indication that it did not complete.
! Synchronous Blocking Architecture
Designing agents as synchronous request-response systems. For any agent that takes more than a few seconds, this creates terrible user experience and brittle infrastructure.
Design agentic workloads as async jobs. Accept the task, return a job ID immediately, run the agent in the background, and provide a status endpoint. Use WebSockets or SSE to stream intermediate results to the client.
📈 The Market and What's Coming
$47B
Market by 2030
Projected global agentic AI market, up from $7.4B in 2025. CAGR of ~44%. Financial services leads adoption followed by healthcare and tech.
68%
Enterprise Adoption
Of Fortune 500 companies have at least one agentic AI pilot in production or active evaluation as of early 2025, per Gartner survey data.
200K+
Context Windows
Claude and Gemini support 200K+ token contexts. By 2026, million-token contexts are expected to become standard, fundamentally changing memory architecture tradeoffs.
97M+
MCP SDK Downloads/mo
Monthly downloads of the MCP SDK as of late 2025, confirming rapid adoption of the protocol as a de-facto standard for AI tool integration.
The bottleneck in agentic AI is no longer the model's capability - it is the infrastructure, the tooling, and the engineering discipline required to deploy these systems reliably at scale.
★ Demystified: LLM vs RAG vs AI Agent vs Agentic AI vs MCP
These five terms are used interchangeably in the industry and almost always incorrectly. They represent fundamentally different layers of a stack, not synonyms for "AI thing." The LLM is the reasoning engine. RAG is how you feed it knowledge. An AI Agent is how it acts. Agentic AI is the architectural philosophy. MCP is the integration protocol that connects them all. Here is a complete breakdown of each - with architecture, tradeoffs, real examples, and when to use each.
💡 The One-Line Mental Model
LLM = the brain · RAG = feeding the brain with current knowledge · AI Agent = giving the brain hands to act · Agentic AI = a system of brains collaborating autonomously · MCP = the USB-C connector standardizing how every brain plugs into every tool
🧠
Large Language Model (LLM)
// The Foundation Layer
Definition
A deep learning model trained on massive text corpora - books, code, the web - that learns to predict and generate language. It encodes world knowledge, reasoning patterns, and language structure into billions of parameters. Examples: GPT-4o, Claude Sonnet 4.6, Llama 3.1, Gemini 1.5 Pro, Mistral.
Architecture
Transformer-based autoregressive model. Self-attention layers model long-range token dependencies. Trained via next-token prediction on web-scale data, then aligned via RLHF or RLAIF. Inference = forward pass through N billion parameters. Context window (128K-1M tokens) defines working memory.
Text generation, summarization, translation, code generation, classification, reasoning, instruction-following. Operates purely in-context - no memory, no action, no retrieval by default.
Typical Use Cases
Copilots, content generation, code completion (GitHub Copilot), document summarization, Q&A on static knowledge, customer-facing chatbots with bounded scope.
Tool Integration
❌ None by default. The model generates text about tools but cannot call them. Function-calling APIs (OpenAI, Anthropic) are an extension, not native LLM capability.
Memory & Learning
In-context only - whatever fits in the context window. No persistent memory. Knowledge frozen at training cutoff. Can be fine-tuned to update or specialize knowledge, but this is expensive.
Planning & Reasoning
Single-pass: input → output. Can reason within a single generation (Chain-of-Thought), but cannot iterate, reflect on tool results, or course-correct across multiple steps autonomously.
Automation Capability
⚡ Low. Text is produced, not actions. Requires a surrounding system to turn output into automation.
Cost Profile
$ Low per call (fractions of a cent per 1K tokens for smaller models). Cost scales with context length and output tokens. Frontier models (GPT-4o, Claude Opus) cost significantly more per token.
Implementation Time
⏱️ Hours to days. A basic API integration can be done in an afternoon. Fine-tuning takes days to weeks depending on dataset size.
Strengths
✓ Versatile, fast, low-latency, simple to deploy, well-understood. Excellent at language tasks requiring creativity, style, or broad knowledge synthesis.
Weaknesses
✗ Knowledge cutoff. Hallucinations. No real-time data. No actions. Context window is finite working memory. Cannot remember past sessions.
Real-Life Examples
ChatGPT (pre-plugins), Claude.ai in basic chat mode, GitHub Copilot completions, Grammarly rewrites, customer service bots with no tool access.
When To Use
Your problem is a language task on knowledge the model already has, latency must be minimal, the domain is stable, or you're building a proof of concept before adding complexity.
📚
Classic RAG (Naive RAG)
// Retrieval-Augmented Generation · The Knowledge Layer
Definition
A hybrid AI pattern introduced in 2020 (Lewis et al., Meta AI) that augments LLM generation by first retrieving relevant documents from an external knowledge base, then injecting them into the prompt. The LLM never needs retraining - the knowledge arrives at inference time. Classic/Naive RAG follows a strict linear pipeline: Index → Retrieve → Generate.
Architecture
Offline: Documents → Chunking → Embedding model → Vector store (Pinecone, Chroma, Weaviate, pgvector). Online: User query → Embed query → ANN similarity search → Top-K chunks → Inject into prompt → LLM generates answer.
Grounds LLM responses in a private or up-to-date knowledge base. Dramatically reduces hallucination for domain-specific queries. Enables source citation and traceability. Keeps the knowledge layer separate from the model layer.
Typical Use Cases
Enterprise document Q&A, internal knowledge bases, legal/compliance chatbots, customer support over product docs, medical information systems, HR policy assistants.
Tool Integration
⚡ Minimal. The retriever is a tool, but it's implicit and singular. No dynamic tool selection, no API calls, no action execution.
Memory & Learning
Persistent knowledge through the vector store (can be updated by re-indexing). No conversational memory across sessions by default. No adaptive learning - the retriever cannot improve its queries based on feedback.
Planning & Reasoning
Single-stage: one retrieval, one generation. Cannot reason about whether it retrieved the right information. Cannot decompose multi-part queries into sub-retrievals. Cannot loop back if the retrieved context is insufficient.
Automation Capability
⚡ Passive. Answers questions but cannot take actions or trigger workflows.
Cost Profile
$$ Moderate. Embedding cost (one-time indexing + per-query embedding). Vector DB hosting. LLM call per query. Cheaper than agent loops but more expensive than bare LLM.
Implementation Time
⏱️ Days to 2 weeks. LangChain/LlamaIndex provide good boilerplate. Main effort is chunking strategy, embedding choice, and retrieval quality tuning.
Strengths
✓ Reliable, explainable, source-cited. Excellent for known-document Q&A. No model retraining needed. Straightforward to audit and debug. Well-understood failure modes.
Weaknesses
✗ Retrieval precision degrades with noisy corpora. No dynamic query refinement. Cannot handle multi-hop reasoning. Top-K retrieval can miss the best chunk. Context window pressure with large documents.
Real-Life Examples
Notion AI Q&A over workspace · Confluence AI assistant · Intercom Fin (v1) · Perplexity.ai (basic mode) · Most enterprise "chat with your docs" products built in 2023.
When To Use
Your knowledge base is stable, queries are single-hop ("what does policy X say?"), source citation matters, you need explainability, and hallucination reduction is the primary goal.
An evolution of Classic RAG that adds optimization stages both before retrieval (query transformation) and after retrieval (re-ranking, filtering, compression) to improve accuracy and relevance. Advanced RAG addresses the core failure modes of naive pipelines through additional processing layers without changing the fundamental linear flow.
Dramatically higher retrieval precision and recall vs naive RAG. Handles ambiguous, multi-part, and domain-specific queries. Produces more concise and relevant context injection, reducing prompt bloat and LLM confusion.
Typical Use Cases
Legal research assistants, financial analysis over 10-K filings, clinical decision support, developer documentation Q&A over large multi-version codebases, competitive intelligence platforms.
Tool Integration
⚡ Limited. May include hybrid retrievers from multiple sources but still no general tool calling or action execution. The "tools" are retrieval tools only.
Memory & Learning
Richer indexing with metadata and chunk relationships (parent-child, hierarchical). Can incorporate user feedback to refine re-ranking models. Episodic query cache. Still no cross-session conversational memory by default.
Planning & Reasoning
Limited self-reflection. Query transformation implies reasoning about what to retrieve, but this is rule-based or templated. Cannot iteratively retrieve and reason in a loop. Adaptive RAG variants (FLARE, Self-RAG) blur this boundary.
Automation Capability
⚡ Still passive. Produces better answers but takes no actions.
Cost Profile
$$$ Moderate-to-high. Additional LLM calls for query rewriting and re-ranking. Cross-encoder re-ranking is computationally expensive. Latency increases 2-3x vs naive RAG. Cost well justified by accuracy gains in high-stakes domains.
Implementation Time
⏱️ 2-6 weeks. LlamaIndex and LangChain provide most building blocks. Main effort is tuning chunking, embedding model selection, and re-ranker configuration for your specific domain.
Strengths
✓ Significantly better accuracy than classic RAG. Handles ambiguous queries. Reduces irrelevant context injection. Scales to large, noisy corpora. Explainable and debuggable.
Weaknesses
✗ Higher latency and cost. More complex pipeline to debug. Still no multi-hop reasoning across sessions. Requires domain expertise to tune. Cannot take actions or access data not in the vector store.
Real-Life Examples
Harvey AI (legal) · Glean (enterprise search with re-ranking) · Perplexity Pro (with re-ranking layer) · Microsoft Copilot for M365 (semantic re-ranking over SharePoint + Exchange) · Vectara enterprise platform.
When To Use
Classic RAG accuracy is insufficient, your corpus is large/noisy/multi-domain, queries are ambiguous or complex, you need consistent high-accuracy answers, or the domain is regulated and wrong answers have consequences.
🔁
Agentic RAG
// Dynamic Multi-Source Retrieval with Reasoning Loop
Definition
The integration of AI agents into the RAG pipeline. Instead of a static Retrieve → Generate sequence, the agent decides when and how to retrieve, can query multiple sources, can evaluate the quality of retrieved context, and iterates until it has sufficient information to generate a reliable answer. Agentic RAG is RAG + decision-making + action capability.
Architecture
Agent orchestration loop (ReAct or Plan-and-Execute) wrapping multiple retrieval tools: vector store search · web search · SQL query · API call · knowledge graph traversal. The agent chooses which retrieval tool to call, evaluates results, decides whether to retrieve again or generate, and may call non-retrieval tools (calculators, code runners) mid-loop.
Multi-hop reasoning over distributed knowledge sources. Adaptive query strategies - retrieves differently based on what it already knows. Can pull from internal docs, external APIs, and live web in a single reasoning chain. Self-corrects when retrieved context is contradictory or insufficient.
Typical Use Cases
Complex research assistants synthesizing internal + external sources · Financial research agents querying databases + earnings calls + live market data · Medical literature synthesis · Enterprise Q&A where "the answer" may span 5 different internal systems.
Tool Integration
✅ Rich. Multiple retrieval tools + optional action tools. The agent dynamically selects which tool to invoke based on the current state of its reasoning.
Memory & Learning
In-context working memory during a run. Can write retrieved summaries to session memory to avoid re-retrieval. Episodic memory across runs for frequently-asked question optimization. Vector stores provide the persistent knowledge layer.
Planning & Reasoning
Explicit. The agent reasons about whether it has enough information, which source to consult next, and whether retrieved context is relevant and sufficient. Can dynamically decompose multi-hop questions into sub-queries executed across different sources.
Automation Capability
⚡ Moderate. Primarily for answering complex questions, but the agent loop can trigger actions as a side effect. Not primarily an action-taking system.
Cost Profile
$$$$ High. Multiple LLM calls per query (reasoning, tool selection, evaluation). Multiple retrieval calls. Latency is higher than static RAG. Cost increases with query complexity and number of sources.
Implementation Time
⏱️ 4-8 weeks. Requires agent framework integration, multi-source connector setup, and careful design of retrieval tool descriptions. Testing multi-hop queries is time-intensive.
Strengths
✓ Handles complex, multi-hop, multi-source questions that static RAG cannot. Self-correcting. Can synthesize contradictory sources. Adapts retrieval strategy dynamically. Far higher answer quality for complex research tasks.
Weaknesses
✗ Expensive and slow. Loops can get stuck or over-retrieve. Harder to predict and debug than static pipelines. Retrieval quality still bounded by source coverage.
Real-Life Examples
Perplexity Pro Deep Research mode · OpenAI Deep Research · ChatGPT with connected memory + browsing + code interpreter · Glean with agentic query planning · NVIDIA AI-Q Blueprint for enterprise agentic RAG.
When To Use
Questions require synthesizing information across multiple disparate sources, the answer requires multi-hop reasoning, you need to handle "I'm not sure - let me look at another source" scenarios, or classic RAG consistently misses multi-part queries.
🤖
AI Agent
// The Action Layer · Goal-Driven Autonomous Executor
Definition
An LLM equipped with tools, memory, and an execution loop that can take real actions in the world to achieve a goal. Unlike RAG (which answers questions), an agent executes tasks. It can write to databases, call APIs, send emails, run code, navigate browsers, interact with operating systems. The LLM is the decision-making core; the agent is the complete system around it.
Architecture
LLM Core + Tool Registry + Memory System + Orchestration Loop. The loop: perceive state → reason → select action → execute tool → observe result → update state → repeat. Terminates on goal completion, max steps, or human escalation. Memory layers: in-context (active), external key-value (persistent facts), vector (semantic recall), episodic (run history).
Core Components
LLM with function-calling API · Tool registry (web search, code executor, database client, REST API clients, browser automation) · State management · Memory layers · Termination conditions · Human-in-the-loop checkpoints · Observability hooks.
Primary Functionality
Task execution - not just answering, but doing. Booking, purchasing, coding, testing, filing, summarizing and routing, data processing, report generation, workflow automation. Anything a human could do in a digital environment with the right access.
Typical Use Cases
IT ticket triage and resolution · DevOps automation (CI/CD triggers, incident response) · Software development (Claude Code, Devin) · Data analysis and reporting · Email triage and drafting · Travel planning and booking · Research compilation.
Tool Integration
✅ Native and central. Tool use is the defining feature of an agent. Any function that can be wrapped in a schema can be a tool. MCP standardizes the integration layer.
Memory & Learning
Multi-layer memory: working context (in-context) + persistent external memory (K/V store, SQL) + semantic memory (vector DB) + episodic logs. Can improve over time via episodic memory review, though requires explicit design.
Planning & Reasoning
Core capability. ReAct, Plan-and-Execute, Tree-of-Thoughts, and other patterns all apply. The agent actively reasons about the next step at each loop iteration and can revise its plan when tool results are unexpected.
Automation Capability
✅ High. Agents are the primary vehicle for AI automation. Designed to execute multi-step workflows with minimal human intervention within defined boundaries.
Cost Profile
$$$$ High and variable. Cost = (number of steps) × (LLM tokens per step) + tool execution costs. A simple 3-step agent is cheap; a 20-step research agent with multiple retrieval calls can cost dollars per run. Budget carefully.
Implementation Time
⏱️ 1-4 weeks for simple agents; 2-3 months for production-grade agents with full observability, error handling, human escalation, and security hardening.
Strengths
✓ Transforms AI from "advisor" to "executor." Can handle complex, multi-step, goal-oriented tasks. Composable - can incorporate RAG as a tool. Most powerful AI automation primitive available today.
Weaknesses
✗ Expensive at scale. Can loop, hallucinate actions, or take unexpected paths. Security surface area is large (prompt injection, privilege escalation). Requires robust observability and guardrails to be safe in production.
Real-Life Examples
Claude Code · Devin (coding agent) · AutoGPT · GitHub Copilot Workspace · ServiceNow AI Agent · Salesforce Agentforce · Google Vertex AI Agents · Customer support agents (Sierra AI, Intercom Fin v2).
When To Use
Your task has multiple steps, requires interacting with external systems, cannot be completed in a single LLM generation, benefits from iterative refinement, or needs to be automated end-to-end with minimal human touchpoints.
🌐
Agentic AI
// The Architectural Philosophy · Multi-Agent Autonomous Systems
Definition
An architectural paradigm and design philosophy for building AI systems that operate autonomously toward goals, often spanning multiple agents, tools, memory systems, and workflows. Where "AI Agent" refers to a single actor, "Agentic AI" refers to the broader system and philosophy: autonomous, goal-directed, adaptive, capable of managing complex multi-step workflows with minimal human intervention.
Architecture
Networks of specialized agents coordinated by an orchestrator. Common topologies: Hierarchical (orchestrator + workers), Sequential (pipeline), Collaborative (debate/critique). Each agent has its own LLM, tools, and memory. Communication via structured messages, shared state, or a message broker. Often includes RAG pipelines as sub-components.
End-to-end automation of complex, multi-domain workflows. Self-organizing task distribution across specialized agents. Dynamic adaptation to changing conditions mid-execution. Parallel workstream management. Example: receive a business objective, decompose into research/analysis/reporting/communication workstreams, coordinate all agents, deliver final output.
Typical Use Cases
Autonomous software development pipelines (plan → code → test → deploy) · End-to-end sales operations (research lead → draft outreach → schedule follow-up) · Enterprise workflow automation · Autonomous scientific research · Multi-domain customer service (tier-1 to tier-3 escalation with no human handoff).
Tool Integration
✅ Comprehensive. Every agent in the system has its own tool set. MCP is the standardization layer increasingly used to manage this. Tool calling spans APIs, databases, code execution, external services, and other agents.
Memory & Learning
Full memory stack: in-context (per agent) + shared state (across agents in a run) + long-term external memory (across runs) + semantic memory (vector retrieval) + episodic memory (run history for improvement). More sophisticated Agentic AI systems implement meta-learning over episodic data.
Planning & Reasoning
Multi-level: high-level goal decomposition by orchestrator + local step planning by each worker agent. Can re-plan dynamically when sub-tasks fail. Can parallelize independent workstreams. Supports critic/validator agents that check the quality of other agents' outputs.
Automation Capability
✅ Maximum. Agentic AI is the frontier of AI automation - from fully autonomous workflows to human-supervised pipelines with minimal touchpoints. The closest thing to delegating an entire job function to AI.
Cost Profile
$$$$$ Highest. Multiple agents × multiple steps × LLM tokens per step. A 5-agent pipeline for a complex research task can cost $5-20 per run with frontier models. Requires explicit cost budgeting and token monitoring. ROI must be clearly defined.
Implementation Time
⏱️ 3-6 months for a production-ready system. Includes: agent design, tool integration, state management, observability, security hardening, human escalation design, load testing, and failure mode analysis.
Strengths
✓ Can automate entire workflows end-to-end. Specialized agents dramatically outperform generalist agents on their domain. Parallelism enables fast execution of multi-step tasks. The most powerful pattern for enterprise AI transformation.
Weaknesses
✗ High complexity, cost, and operational overhead. Failure modes compound - a bad output from Agent 2 corrupts Agent 3's input. Requires mature observability. Security surface is very large. Difficult to debug without distributed tracing.
Real-Life Examples
Cognition AI's Devin (autonomous software engineer) · OpenAI Operator (browser automation agent) · Anthropic Projects with Claude Code · Salesforce Agentforce multi-agent workflows · AWS Bedrock multi-agent orchestration · Google Cloud Vertex AI Agent Engine.
When To Use
The task spans multiple domains requiring specialized expertise, end-to-end automation of a complex workflow has a clear business case, the cost of human execution significantly exceeds AI cost, and you have the engineering maturity to operate distributed AI systems safely.
🔌
Model Context Protocol (MCP)
// The Integration Standard · "USB-C for AI"
Definition
An open standard protocol introduced by Anthropic in November 2024 that standardizes how AI systems - particularly LLMs and agents - connect to external tools, data sources, and services. Before MCP, connecting an AI model to N tools required N custom integrations (the "N×M problem"). MCP provides a single universal interface: one protocol, any model, any tool. Now governed by the Linux Foundation / Agentic AI Foundation (as of December 2025), with adoption by OpenAI, Google DeepMind, and Microsoft.
Architecture
Client-server over JSON-RPC 2.0. Host: The AI application (Claude Desktop, Cursor, an agent framework) - manages connections and security policies. Client: Lives inside the host; maintains a 1:1 stateful session with one MCP server; handles protocol negotiation. Server: Exposes Tools (executable functions), Resources (data/documents), and Prompts (templates) through a standardized interface. Servers can be local processes or remote services.
Core Components
Protocol primitives: Tools (code execution) · Resources (data access: files, DB rows, API responses) · Prompts (reusable templates) · Sampling (server-side LLM calls) · Roots (filesystem scope) · Elicitation (structured user input). Transport: JSON-RPC 2.0 over stdio (local), HTTP+SSE, or WebSocket (remote).
Primary Functionality
Standardizes tool and context integration so that a tool built once (e.g., a GitHub MCP server) works with any MCP-compatible AI client. Eliminates bespoke connector code. Provides context preservation across multi-turn interactions. Enables tool discovery - agents can query available tools at runtime rather than having them hardcoded.
Typical Use Cases
AI IDEs (Cursor, Claude Code) accessing codebases and running tests · Enterprise agents connecting to Salesforce, Jira, Confluence, GitHub via standardized MCP servers · RAG pipelines exposing document stores as MCP resources · Multi-agent systems sharing a common tool catalog · DevOps agents controlling K8s, cloud providers, CI systems.
Tool Integration
✅ This is MCP's core value proposition. It IS the integration layer. Any service with an MCP server is instantly accessible to any MCP-compatible AI. 97M+ monthly SDK downloads confirm rapid ecosystem growth.
Memory & Learning
MCP is not a memory system itself but enables memory systems. Resources can expose memory stores (vector DBs, K/V stores) as first-class MCP resources. Session IDs provide context continuity within a connection. Persistent context across sessions requires an external memory service exposed via MCP.
Planning & Reasoning
MCP does not plan or reason - it is a protocol. But it enables richer planning by making a larger, standardized tool surface available to the reasoning LLM. Agents that use MCP can discover and invoke tools they were not explicitly programmed with.
Automation Capability
🔌 Enabler. MCP dramatically lowers the cost of building automated agents by eliminating custom connector code. It is infrastructure, not the automation itself - but it makes high-quality automation significantly easier to build.
Cost Profile
$ Protocol overhead is minimal. Running MCP servers locally is near-zero cost. Remote MCP servers have the hosting cost of the wrapped service. Integration cost savings (replacing N custom connectors with N MCP servers) often justify the adoption investment within weeks.
Implementation Time
⏱️ Hours to days per MCP server. Official SDKs in Python, TypeScript, C#, Java. Anthropic maintains a reference library of pre-built MCP servers (GitHub, filesystem, databases, Slack). For complex enterprise integration: days to 2 weeks including security and permission scoping.
Strengths
✓ Solves the N×M integration problem. Write once, use everywhere. Vendor-neutral (Linux Foundation governed). Rapidly becoming industry standard. Enables tool marketplace/discovery. Dramatically reduces integration boilerplate. Compatible with A2A (Google's agent-to-agent protocol) - they solve different problems and compose together.
Weaknesses
✗ Security model requires careful implementation - prompt injection via MCP tool responses is a real risk. Permission scoping is developer responsibility. Protocol still maturing (v2025-11-25). Tool descriptions are untrusted unless server is explicitly trusted. Adds a protocol layer that can complicate debugging.
Real-Life Examples
Claude Desktop + GitHub MCP server (code access) · Cursor IDE with filesystem + Git MCP · Windsurf editor · AWS/GCP/Azure providing MCP servers for their APIs · Cloudflare MCP server deployment · IBM BeeAI · Microsoft Copilot Studio with MCP connectors · Any tool in Anthropic's public MCP server registry.
When To Use
You are building an AI system that needs to connect to external tools or data sources and you want to avoid writing custom connector code for each. Especially valuable when: building multi-agent systems that need a shared tool catalog, wanting tool portability across AI clients, or operating in an enterprise environment that wants a governed, auditable integration layer.
Quick-Reference Comparison Matrix
Dimension
LLM
Classic RAG
Advanced RAG
Agentic RAG
AI Agent
Agentic AI
MCP
Takes Actions?
❌
❌
❌
⚡ Limited
✅
✅✅
🔌 Enables
External Knowledge
❌ Frozen
✅ Static
✅ Optimized
✅ Dynamic
✅ Via tools
✅ Full stack
🔌 Standardizes
Multi-step Reasoning
⚡ CoT only
❌
⚡ Limited
✅
✅
✅✅
N/A
Persistent Memory
❌
⚡ Vector store
⚡ Vector + meta
✅ Multi-layer
✅ Multi-layer
✅ Full stack
🔌 Via Resources
Tool Integration
❌
⚡ Retrieval only
⚡ Retrieval only
✅ Multi-source
✅ General
✅ Per-agent
✅ IS the layer
Relative Cost
$
$$
$$$
$$$$
$$$$
$$$$$
$
Implementation Time
Hours
Days
Weeks
Weeks
Weeks-months
Months
Hours-days
Hallucination Risk
High
Low-Med
Low
Low
Med (actions)
Med (compounding)
N/A
Human Oversight Needed
Per response
Per response
Periodic
Checkpoints
Checkpoints
Governance layer
Permission scoping
Which Pattern Should You Use? - Decision Framework
// Decision Framework - Start at the top, stop when you find your answer
Is this a single-turn text task on knowledge the model already has?
→ Bare LLM. No retrieval, no agent. Writing, summarization, Q&A on stable facts, code generation from spec. Add complexity only when the LLM alone is insufficient.
Does accuracy require access to private/updated knowledge with source traceability?
→ Classic RAG if your queries are straightforward. Upgrade to Advanced RAG if the corpus is large/noisy or accuracy requirements are high. Both are passive answer systems - no actions taken.
Does answering require synthesizing across multiple sources or multi-hop reasoning?
→ Agentic RAG. The agent decides which sources to consult, iterates until it has sufficient context, and synthesizes across heterogeneous data. Higher cost but significantly better answer quality for complex research queries.
Does the task require taking actions in external systems (write DB, call API, send email, run code)?
→ AI Agent. Not just answering - doing. Design the tool set carefully, implement max step limits and observability from day one, scope permissions to minimum necessary. Start simple, add complexity based on production learnings.
Does the workflow span multiple domains, requiring specialized expertise at each stage?
→ Agentic AI (multi-agent). An orchestrator + specialized worker agents. Only adopt this when a single general-purpose agent demonstrably fails due to capability or reliability limitations - the operational overhead is significant.
Are you building multiple agents/tools and want to avoid writing custom connectors for each integration?
→ Adopt MCP as your integration layer. It is not a replacement for any of the above - it is orthogonal infrastructure that reduces integration cost across your entire AI stack. Use it everywhere you need to connect AI to tools or data sources.
✅ The Stack in Practice
In production, these patterns compose rather than compete. A real enterprise system might look like: an Agentic AI multi-agent workflow, where each agent uses the LLM as its reasoning core, incorporates Advanced RAG for knowledge retrieval, executes actions via tools registered in an MCP server, and occasionally spawns an Agentic RAG sub-routine for complex research queries. Understanding each layer independently is the prerequisite for composing them well.
Agents Are Not Magic - They Are Engineering
The most important lesson from teams that have successfully deployed agentic systems in production is that the hard work has nothing to do with prompting and everything to do with engineering. The loop, the tools, the memory, the observability, the error handling, the human escalation paths - these are the same engineering problems that exist in any distributed system, just with a language model in the middle.
Start with the simplest pattern that could possibly solve your problem: a bare LLM before RAG, RAG before an agent, one agent before a multi-agent system. Add layers only when you hit a concrete limitation. Measure token consumption and success rate from day one. Build observability before you build features.
And accept that your agents will fail in ways you cannot predict - the goal is not to prevent failure, it is to detect it fast, understand it clearly, and fix it before it compounds.
Start with one tool, one loop, one goal →
This article reflects the state of agentic AI development as of April 2026. Sources include IBM Think, NVIDIA Developer Blog, Anthropic documentation, Wikipedia MCP article (updated April 2026), DigitalOcean Conceptual Articles, Analytics Vidhya, Fractal.ai, Sprinklr, Meilisearch, MarkTechPost, and the official MCP specification (v2025-11-25). All code examples are illustrative and simplified for clarity; production implementations require additional error handling, security hardening, and infrastructure considerations.